Part 2. 분산 데이터
지난 몇 개 장에서 되풀이됐던 주제는 시스템이 잘못된 것을 어떻게 처리하느냐였다(복제 서버 장애 복구, 복제 지연, 트랜잭션의 동시성 제어 등). 실제 환경의 시스템에서 나타날 수 있는 다양한 에지 케이스를 잘 이해할수록 이것들을 잘 처리할 수 있다.
이렇게 결함에 대한 이야기를 많이 했지만, 아직도 너무나 낙관적이다. 현실은 훨씬 더 비관적이다. 이제부터 잘못될 가능성이 있다는 것들은 모두 잘못된다고 가정한다.
분산 시스템은 단일 컴퓨터에서 실행하는 소프트웨어를 작성하는 일과는 근본적으로 다르다. 이번 장에서는 네트워크 관련 문제와 시계/타이밍 문제를 조사하고, 이것들을 어느 정도로 회피하여, 분산 시스템을 유지할 수 있도록 보장을 제공하는 알고리즘을 살펴본다.
결국 엔지니어로서의 우리의 임무는 모든 게 잘못되더라도 제 역할을 해내는 시스템을 구축하는 것이다.
결함과 부분 장애
단일 컴퓨터에서 프로그램은 상당히 예측 가능한 방식으로 동작한다(동작하거나, 동작하지 않거나). 그 이유는 하드웨어가 올바르게 동작하면 같은 연산은 항상 같은 연산을 내며(결정적이며), 만약 하드웨어 문제가 발생한다면 잘못된 결과를 반환하지 않고 완전히 동작하지 않을 것이기 때문이다. 이는 컴퓨터를 설계할 때 의도적으로 선택한 것이다. 컴퓨터는 구현 기반이 되는 불분명한 물리적 현실을 감추고, 수학적 완벽함을 갖고 동작하는 이상화된 시스템 모델을 보여준다.
하지만 네트워크로 연결된 여러 컴퓨터에서 실행되는 소프트웨어에서는 상황이 근본적으로 다르다. 분산 시스템에서 이상화된 시스템 모델은 동작하지 않으며, 물리적 세계의 지저분한 현실을 마주하게 된다(전원 장애, 스위치 장애, HVAC 시스템 장애 등).
분산 시스템에서는 시스템의 어떤 부분은 잘 동작하지만 다른 부분은 예측할 수 없는 방식으로 고장날 수 있다. 이를 partial failure(부분 장애)라고 한다. 부분 장애는 비결정적이기 때문에 어떨 때는 동작하지만 어떨 떄는 실패한다. 심지어 뭔가 성공했는지도 알지 못할 수도 있는데, 이는 메시지가 네트워크를 거쳐 전송되는 시간도 비결정적이기 때문이다.
비결정성과 부분 장애 가능성이 분산 시스템을 다루기 어렵게 한다.
클라우드 컴퓨팅과 슈퍼컴퓨팅
대규모 컴퓨팅 시스템 구축 방법에 관한 몇 가지 철학이 있다.
- 대규모 컴퓨팅의 한쪽 끝에는 high-performance computing, HPC(고성능 컴퓨팅) 분야가 있다. 수천 개의 CPU를 가진 슈퍼컴퓨터는 보통 일기예보나 분자 동력학처럼 계산 비용이 매우 높은 과학 계산 작업에 쓰인다.
- 다른 극단에는 클라우드 컴퓨팅이 있다. 명확히 정의되지는 않지만, 멀티 테넌트 데이터센터, IP 네트워크(Ethernet으로 연결된)로 연결된 commodity(상용) 컴퓨터, elastic/on-demand(신축적/주문식) 자원 할당, metered billing(계량 결제)와 흔히 관련돼 있다.
- 전통적인 기업형 데이터센터는 이 두 극단의 중간 지점에 있다.
이런 철학에 따라 결합 처리 방법도 매우 다르다.
고성능 컴퓨팅의 경우 작업을 체크포인트로 지속성 있는 저장소에 저장한다. 만약 노드 하나에 장애가 난다면 전체 클러스터를 멈추고, 작업부하를 중단하는 것이다. 복구 후에는 마지막 체크포인트부터 계산을 재시작한다.
이 책에서는 인터넷 서비스를 구현하는 시스템을 집중적으로 다루며, 이는 보통 슈퍼컴퓨터와 매우 다르다.
지속성
- 날씨 시뮬레이션 같은 오프라인(일괄 처리) 작업은 멈췄다 재시작해도 충격이 덜하다.
- 반면 여러 인터넷 관련 애플리케이션은 언제라도 사용자에게 지연 시간이 낮은 서비스를 제공해야 한다는 점에서 온라인이다. 수리를 위해 클러스터를 중단시키는 것처럼 서비스를 이용할 수 없게 하는 것은 허용되지 않는다.
하드웨어
- 슈퍼컴퓨터는 전형적으로 특화된 하드웨어를 사용해 구축한다. 각 노드는 매우 신뢰성이 높으며 노드 사이에는 공유 메모리와 remote direct memory access, RDMA(원격 직접 메로리 접근)을 사용해 통신한다.
- 반면 클라우드 서비스의 노드는 상용 장비를 사용해 구축한다. 규모의 경제 덕에 낮은 비용으로 동일한 성능을 제공하지만 실패율도 높다.
네트워크
- 거대한 데이터센터의 네트워크는 흔히 IP와 이더넷을 기반으로 하며 높은 bisection bandwidth(양단 대역폭)을 제공하기 위해 Clos topoloy(클로스 토폴로지)로 연결돼 있다.
- 반면 슈퍼컴퓨터는 통신 패턴이 정해진 HPC 작업부하에서 높은 성능을 보여주는 다차원 mesh(메시)나 torus(토러스) 같은 특화된 네트워크 토폴로지를 자주 사용한다.
고장
- 시스템이 커질수록 구성 용소 중 하나가 고장날 가능성도 높아진다. 시간이 지나면서 고장난 것은 수리되고 새로운 것이 고장나지만 수천 개의 노드가 있는 시스템에서는 항상 뭔가 고장난 상태라고 가정하는 게 합리적이다. 오류 처리 전략에 그냥 포기하는 것을 포함한다면 대형 시스템은 유용한 일을 하기보다 결함으로부터 복구하는 데 많은 시간을 쓰게 될 수도 있다.
운영/유지보수
- 시스템이 장애가 난 노드를 감내할 수 있고 전체적으로는 계속 동작할 수 있다면 이는 운영과 유지보수에 매우 유용한 특성이 된다. 이를테면 끊김 없이 사용자에게 서비스를 계쏙 제공하면서 한 번에 노드 하나씩 재시작하는 순회식 업그레이드를 할 수 있다. 클라우드 환경에서 가상 장비 하나의 성능이 좋지 않으면 그냥 그것을 죽이고 새 가상 장비를 요청할 수 있다(새로 할당된 것은 더 빠르기를 바라면서).
배포
- 지리적으로 분산된 배포(지연 시간을 줄이기 위해 사용자와 지리적으로 가까운 곳에 데이터를 보관)를 할 때 통신은 대부분 인터넷을 거치기 쉬운데, 이는 로컬 네트워크에 비해 느리고 신뢰성도 떨어진다.
- 반대로 슈퍼컴퓨터는 일반적으로 모든 노드가 가까운 곳에 함께 있다고 가정한다.
분산 시스템이 동작하게 만들렴녀 부분 장애 가능성을 받아들이고 소프트웨어에 내결함성 메커니즘을 넣어야 한다. 바꿔 말하면 신뢰성 없는 구성 요소를 사용해 신뢰성 있는 시스템을 구축해야 한다.
몇 개의 노드로만 구성된 작은 시스템이라도 부분 장애를 고려하는 것은 매우 중요하다. 구성 요소들이 대부분 올바르게 동작하겠지만, 조만간 어떤 부분에 결함이 생길 것이고, 소프트웨어가 그 결함을 처리해야 한다. 결함 처리는 소프트웨어 설계의 일부여야 한다. 분산 시스템에서 생길 수 있는 결함을 광범위하게 고려하고 테스트하는 것이 중요하다.
신뢰성 없는 네트워크
이 책에서 주로 다루는 분산 시스템은 비공유 시스템, 즉 네트워크로 연결된 다수의 장비다. 각 장비는 자신만의 메모리와 디스크를 갖고 있으며, 다른 장비에 접근하기 위해서는 이 장비들이 통신하는 유일한 수단인 네트워크를 사용해야 한다.
비공유가 시스템을 구축하는 유일한 방법은 아니지만, 몇 가지 이유로 인터넷 서비스를 구축하는 주된 방법이 됐다.
- 특별한 하드웨어가 필요하지 않아서 상대적으로 저렴함.
- 상품화된 클라우드 서비스를 활용할 수 있음.
- 지리적으로 분산된 여러 데이터센터에 중복 배치함으로써 높은 신뢰성을 확보할 수 있음.
인터넷과 데이터센터 내부 네트워크 대부분(흔히 이더넷)은 asynchronous packet network(비동기 패킷 네트워크)다. 이런 종류의 네트워크에서 노드는 다른 노드로 메시지(패킷)를 보낼 수 있지만 네트워크는 메시지가 언제 도착할지 혹은 메시지가 도착하기는 할 것인지 보장하지 않는다. 따라서 요청을 보내고 응답을 기다릴 때 여러 가지가 잘못될 수 있다.
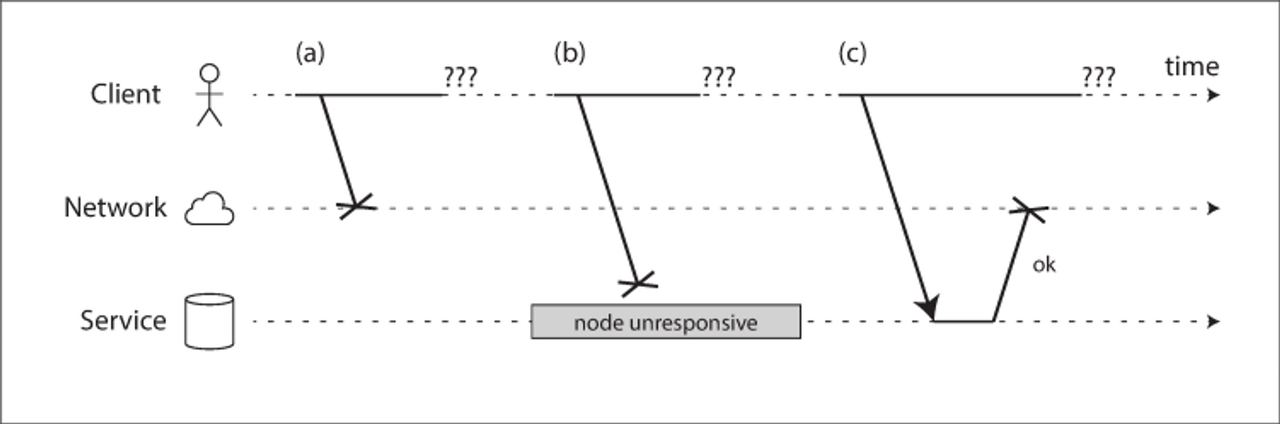
- 요청이 손실됐을 수 있다(누군가 네트워크 케이블을 뽑았을지도 모른다).
- 요청이 큐에서 대기하다 나중에 전송될 수 있다(네트워크나 수신자에 과부하가 걸렸을 수 있다).
- 원격 노드에 장애가 생겼을 수 있다(죽었거나 전원이 나갔을 수 있다).
- 원격 노드가 일시적으로 응답하기를 멈췄지만(가비지 컬렉션 휴지가 길어졌을 수 있다). 나중에는 다시 응답하기 시작할 수 있다.
- 원격 노드가 요청을 처리했지만 응답이 네트워크에서 손실됐을 수 있다(네트워크 스위치의 설정이 잘못됐을 수 있다).
- 원격 노드가 요청을 처리했지만 응답이 지연되다가 나중에 전송될 수 있다(네트워크나 요청을 보낸 장비에 과부하가 걸렸을 수 있다).
결국 전송 측은 패킷이 전송됐는지 아닌지조차 구별할 수 없으며, 그 이유도 알 수 없다. 알 수 있는 유일한 정보는 응답을 아직 받지 못했다는 사실 뿐이다.
이런 문제를 다루는 흔한 방법은 타임아웃이다. 타임아웃을 통해 얼마 간의 시간이 지나면 응답 대기를 멈추고 응답이 도착하지 않는다고 가정한다. 그러나 타임아웃이 발생해도, 원격 노드가 응답을 받았을 수도 있고, 요청이 타임아웃 이후에 도착할 수도 있다.
현실의 네트워크 결함
수십년 동안 컴퓨터 네트워크를 구축했지만, 아직도 신뢰성 있는 네트워크를 구축하는 방법을 찾지는 못했다.
데이터센터처럼 제어된 환경에서도, 네트워크 문제는 다양한 이유로 발생한다. 또한 이런 문제는 네트워크 장비를 중복 추가하는 것으로는 기대만큼 결함을 줄여주지 못한다. 네트워크 중단의 주요 원인인 인적 오류로부터 보호해주지 못하기 때문이다.
EC2 같은 공개 클라우드 서비스 또한 일시적인 네트워크 결함이 자주 발생하며, 네트워크 문제는 소프트웨어 업데이트 떄문에, 상어가 해저 케이블을 물었기 떄문에, 네트워크가 한 방향으로만 흐르는 오류가 발생했기 때문에 발생한다.
결함은 일어날 수 있기 때문에 소프트웨어는 네트워크 결함을 처리할 수 있어야 한다. 그렇지 않으면 클러스터가 교착 상태에 빠지거나, 데이터가 날라가거나, 소프트웨어가 예측 못한 일을 할 수도 있다.
반드시 네트워크 결함을 tolerating(견뎌내도록) 처리할 필요는 없다. 평소에 네트워크가 믿을 만 하다면 간혹 발생하는 오류를 사용자에게 고지하면 된다. 하지만 소프트웨어가 네트워크 문제에 어떻게 반응하는지 알고 시스템이 그로부터 복구할 수 있도록 보장해야 한다. 따라서 Chaos Monkey(카오스 몽키)처럼 시스템을 고의로 고장내고, 이 상황에서의 시스템의 반응을 테스트하는 것이 일리가 있다.
결함 방지
많은 시스템은 결함 있는 노드를 자동으로 감지할 수 있어야 한다. 예를 들어
- 로드 밸런서는 죽은 노드를 그만 보내야 한다(즉, 죽은 노드는 순번에서 빠진 것으로 간주해야 한다).
- 단일 리더 복제를 사용하는 분산 데이터베이스에서 리더에 장애나 나면 팔로워 중 하나가 리더로 승격돼야 한다
하지만 불행하게도. 네트워크에 관한 불확실성 때문에 노드가 동작 중인지 아닌지 구별하기 어렵다. 이런 상황에서 뭔가 동작하지 않는다고 명시적으로 알려주는 피드백을 받을 수도 있다.
- 노드가 실행 중인 장비에 연결할 수 있지만 목적지 포트에서 수신 대기하는 프로세스가 없다면(예를 들어 프로세스가 죽었다면) 운영체제가 친절하게 RST나 FIN 패킷을 응답으로 보내서 TCP 연결을 닫거나 거부한다. 그러나 노드가 요청을 처리하다 죽었으면 원격 노드에서 데이터가 실제로 얼마나 처리됐는지 알 방법이 없다.
- 노드 프로세스가 죽었지만(또는 관리자가 죽였지만) 노드의 운영체제는 아직 실행 중이라면 스크립트로 다른 노드에게 프로세스가 죽었다고 알려서 다른 노드가 타임아웃이 만료되기를 기다릴 필요 없이 빠르게 역할을 넘겨받을 수 있게 할 수 있다. 예를 들어 HBase가 이렇게 한다.
- 데이터센터 내 네트워크 스위치의 관리 인터페이스에 접근할 수 있으면 질의를 보내 하드웨어 수준의 링크 장애(예를 들어 원격 장비의 전원이 내려갔는지)를 감지할 수 있다. 인터넷을 통해 연결하거나, 스위치 자체에 대한 접근을 할 수 없는 공용 데이터센터를 사용하거나, 네트워크 문제 때문에 관리 인터페이스에 연결할 수 없다면 이 선택지를 배제된다.
- 접속하려면 IP 주소에 도달할 수 없다고 라우터가 확신하면 ICMP Destination Unreachable 패킷으로 응답할 수도 있다. 그러나 라우터가 마법 같은 장애 감지 능력이 없다면 네트워크의 다른 참여자들과 동일한 제한이 적용된다.
원격 노드가 다운되고 있다는 빠른 피드백은 유용하지만 여기에 의존할 수는 없다. TCP가 패킷이 전달됐다는 확인 응답(ack)을 했더라도, 애플리케이션 그것을 처리하기 전에 죽을 수도 있다. 요청이 성공했음을 확신하고 싶다면 애플리케이션 자체로부터 긍정 응답을 받아야 한다.
역으로 뭔가 잘못되면 스택의 어떤 수준에서 오류 응답을 받을지도 모르지만 일반적으로 아무 응답도 받지 못할 것이라고 가정해야 한다. 따라서 몇 번 재시도를 해 보고(TCP는 사용자 모르게 재시도를 하지만 애플리케이션 수준에서 재시도할 수도 있다) 타임아웃이 만료되기를 기다렸다가 타임아웃 내에 응답을 받지 못하면 마침에 노드가 죽었다고 선언할 수 있다.
타임아웃과 기약 없는 지연
타임아웃만이 결함을 감지하는 확실한 수단이라면 타임아웃은 얼마나 길어야 할까?
- 만약 타임아웃이 길다면 노드가 죽었다고 선언될 때까지 기다리는 시간이 길어지며, 사용자는 기다리거나 오류 메시지를 봐야한다.
- 만약 타임아웃이 짧다면 결함을 빨리 발견하지만, 노드가 일시적으로 느려졌을 때도 죽었다고 잘못 선언될 수도 있다. 성급하게 노드가 죽었다고 선언하면 문제가 되는데, 해당 노드가 동작을 실행했고, 다른 노드가 또 동작을 실행하여 동작을 2번 실행하게 될 수도 있다. 또한 다른 노드에게 책무가 넘어가는 과정에서 노드와 네트워크에 오버헤드를 줄 수 있다. 만약 과부하 떄문에 노드의 응답이 느렸을 경우, 책무가 넘겨받은 노드가 또 과부화되어 연쇄 장애를 유발할 수 있다.
패킷의 최대 지연 시간이 보장된 네트워크를 가정한다면, 모든 패킷은 어떤 시간 d 내에 전송된다고 볼 수 있으며, 장애가 나지 않은 노드는 항상 요청을 r 시간 내에 처리한다고 볼 수 있다. 따라서 성공한 요청은 모두 2d + r 시간 내에 응답을 받는다고 보장할 수 있다. 이 시간을 초과하면 네트워크나 노드가 동작하지 않는다는 의미하고, 따라서 2d + r을 타임아웃으로 사용할 수 있다.
유감스럽게도 우리가 사용하는 시스템은 대부분 이 중 어떤 것도 보장하지 않는다. 비동기 네트워크는 unbounded delay(기약 없는 지연), 즉 패킷이 도착하는 데 걸리는 시간의 상한치가 없으며, 서버의 처리 속도를 보장할 수도 없다.
네트워크 혼잡과 큐 대기
자동차를 운전할 때 도로 네트워크에서 이동시간이 대부분 교통 체증에 따라 달라지듯이, 컴퓨터 네트워크에서 패킷 지연의 변동성은 큐 대기 떄문인 경우가 많다.
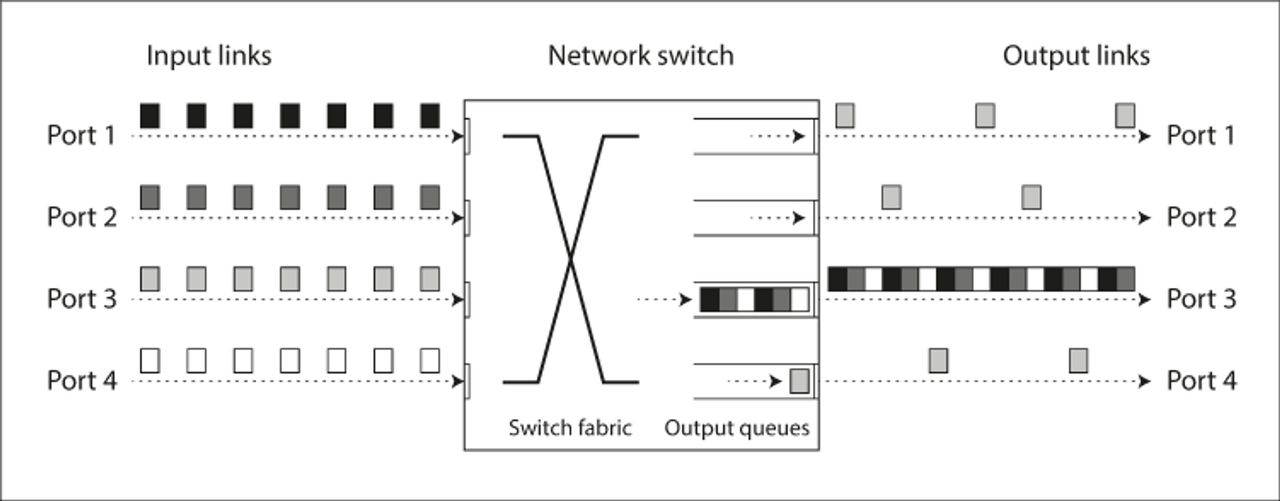
- 위 그림처럼, 여러 다른 노드가 같은 목적지로 패킷을 보내려고 하면 네트워크 스위치는 패킷을 큐에 넣고 한 번에 하나씩 목적지 네트워크 링크로 넘겨야 한다. 네트워크 링크가 붐비면 패킷은 슬롯을 얻을 수 있을 때까지 잠시 기다려야 할 수도 있다(이를 network congestion(네트워크 혼자)이라고 부른다). 네트워크는 잘 동작하고 있더라도 들어오는 데이터가 많아서 스위치 큐를 꽉 채울 정도가 돼면 패킷이 유실되어 재전송해야 한다.
- 패킷이 목적지 장비에 도착했을 때 모든 CPU 코어가 바쁜 상태라면 네트워크에서 들어온 요청을 애플리케이션에서 처리할 준비가 될 때까지 운영체제가 큐에 넣어 둔다. 장비의 부하에 따라 큐에서 대기하는 시간은 제각각일 수 있다.
- 가상 환경에서 실행되는 운영체제는 다른 가상 장비가 CPU 코어를 사용하는 동안 수십 밀리초 동안 멈출 때가 흔하다. 이 시간 동안 가상 장비는 네트워크에서 어떤 데이터도 받아들일 수 없으므로 가상 장비 모니터가 들어오는 데이터를 큐에 넣어서(버퍼링한다) 네트워크 지연의 변동성을 더욱 증가시킨다.
- TCP는 flow control(흐름 제어)를 수행한다. congestion avoidance(혼잡 회피)나 backpressure(배압)이라고도 하는 흐름 제어는 노드가 네트워크 링크나 수신 노드에 과부화를 가하지 않도록 자신의 송신율을 제한하는 것이다. 데이터가 네트워크로 들어가기 전에도 부가적인 큐 대기를 할 수 있다는 뜻이다.
- 또한 TCP는 어떤 타임아웃 안에 확인 응답을 받지 않으면 패킷이 손실됐다고 간주하고 손실된 패킷은 자동으로 재전송한다. 애플리케이션에게는 패킷 손실이나 재전송이 보이지 않지만 재전송으로 생기는 지연은 보인다.
화상 회의나 인터넷 전화(Voice over IP, VoIP)처럼 지연 시간에 민감한 애플리케이션들은 TCP 대신 UDP를 사용한다. UDP는 흐름제어를 하지 않고 손실된 패킷을 재전송하지 않으므로 네트워크 지연이 크게 변하게 하는 원인 중 일부를 제거한다. 전화 통화에서 손실된 패킷을 재전송하기에는 시간이 충분하지 않으므로, 패킷을 재전송하는 것이 의미가 없다. 대신 애플리케이션은 잃어버린 패킷에 해당하느 시간 슬롯을 침묵(소리 잠시 끊김)으로 채우고, 스트림에서 계속 이동해야 한다. 재시도는 사람 계층에서 재시도(”안 들렸어, 다시 말해줘”) 된다.
이 모든 요인이 네트워크 지연의 변동성에 영향을 준다. 큐 대기 지연은 시스템이 최대 용량에 가까울 때 특히 광범위하게 일어난다. 사용률이 높은 시스템일수록 긴 큐가 매우 빨리 만들어진다.
공개 클라우드와 멀티 테넌트 데이터센터에서는 여러 소비자가 자원을 공유한다(네트워크 링크, 스위치, 각 장비의 네트워크 인터페이스와 CPU까지). 따라서 다른 누군가(시끄러운 이웃)이 MapReduce와 같은 일괄 처리 작업부하를 수행하고 있으면 네트워크 링크가 포화되고, 이 때문에 네트워크 지연 변동이 커질 수 있다.
이런 환경에서는 실험적으로 타임아웃을 선택하는 수 밖에 없다. 지연의 변동성을 측정하기 위해서는 긴 기간에 여러 장비에 걸쳐서 네트워크 왕복 시간의 분포를 측정해야 하고, 그 후 애플리케이션의 특성을 고려해서 장애 감지 지연과 너무 이른 타임아웃의 위험성 사이에서 적절한 트레이드오프를 결정할 수 있다.
더 좋은 방법은 고정된 타임아웃을 설정하는 대신, 시스템이 지속적으로 응답 시간과 그들의 변동성(jitter(지터))을 측정하고 관찰된 응답 시간 분포에 따라 타임아웃을 자동으로 조절하게 하는 것이다. Phi Accrual failure detector(파이 증가 장애 감지기)를 쓰면 된다. 이를 사용하는 예로 Akka와 Cassandra가 있다. TCP 재전송 타임아웃도 비슷하게 동작한다.
동기 네트워크 대 비동기 네트워크
패킷 전송 지연 시간의 최대치가 고정돼 있고 패킷을 유실하지 않는 네트워크에 기댈 수 있다면 분산 시스템은 훨씬 더 단순해진다. 왜 하드웨어 수준에서 이 문제를 해결하고 네트워크를 신뢰성 있게 만들어서 소프트웨어에서는 걱정할 필요가 없게 할 수 없을까?
이 질문에 답하기 위해 전화 네트워크와 비교해보자. 전화 네트워크에서 통화를 할 때는 circuit(회선)이 만들어진 후, 보장된 양의 대역폭이 할당된다. ISDN 네트워크의 경우 초당 4,000 프레임의 고정된 비율로 실행된다. 통화는 16비트 공간이므로 250마이크로초마다 정확히 16비트의 오디오 데이터를 보낼 수 있도록 보장된다.
이런 식의 네트워크는 동기식이다. 네트워크의 다음 hop(홉)에 통화당 16비트의 공간이 이미 할당됐기 때문이다. 그리고 큐 대기가 없으므로 네트워크 종단 지연 시간의 최대치가 고정돼 있다. 이를 bounded delay(제한 있는 지연)이라고 한다.
그냥 네트워크 지연을 예측 가능하게 만들 수는 없을까?
TCP는 전화 네트워크의 회선과 매우 다르다. 회선은 고정된 양의 예약된 대역폭이지만 TCP 연결읠 패킷은 동적으로 대역폭을 사용한다. TCP는 가능하면 짧은 시간 안에 전송하려고 할 뿐이다.
데이터센터 네트워크의 이더넷과 IP는 큐 대기의 영향을 받는 packet-switch(패킷 교환) 프로토콜이고, 네트워크에 기약 없는 지연이 있다. 데이터센터 네트워크와 인터넷이 패킷 교환을 사용하는 이유는 bursty traffic(순간적으로 몰리는 트래픽)에 최적화됐기 떄문이다. 초당 비트 개수가 고정돼 있는 음성과 다르게, 웹 페이지, 이메일, 파일 전송 등은 대역폭 요구사항이 없고, 단지 빨리 완료되기를 원한다.
따라서 순간적으로 몰리는 데이터 전송에 고정된 대역폭인 회선을 쓰면 네트워크 용량을 낭비하고 전송이 느려진다. 반면 TCP는 가용한 네트워크 용량에 맞춰 데이터 전송률을 동적으로 조절한다.
ATM(Asynchrounous Transfer Mode)처럼 회선 교환과 패킷 교환을 모두 지원하는 하이브리드 네트워크를 만드려고 시도도 있었다. quality of service, QoS(서비스 품질, 패킷에 우선순위를 매기고 스케줄링함)과 admission control(진입 제어)를 잘 쓰면 패킷 네트워크에서 회선 교환을 흉내 내거나 통계적으로 제한 있는 지연을 제공하는 것도 가능하다.
그러나 이런 서비스 품질은 현재 멀티 테넌트 데이터센터와 공개 클라우드에서 사용할 수 없고 인터넷을 통해 통신할 때도 사용할 수 없다. 현재 배포된 기술로는 네트워크의 지연과 신뢰성에 대해 어떤 보장도 할 수 없다. 네트워크 혼잡, 큐 대기, 기약 없는 지연이 발생할 것이라고 가정해야 한다.
결과적으로 타임아웃에 “올바른” 값은 없으며, 실험을 통해 결정해야 한다.
네트워크에서 변동이 큰 지연은 자연 법칙이라 아니라, 단지 비용/이득 트레이드오프의 결과일 뿐이다. 자원을 정적 분할한다면 지연 시간을 보장할 수 있지만 사용륭이 낮아서 비용이 커지며, 동적 자원 분할을 하는 멀티 테넌트 방식을 쓰면 사용률을 높여서 비용을 줄어들지만 지연의 변동이 큰 단점이 있다.
신뢰성 없는 시계
시계와 시간은 중요하다. 애플리케이션은 다음과 같은 질문에 대답하기 위해 다양한 방식으로 시계에 의존한다.
- 이 요청이 타임아웃됐나?
- 이 서비스의 99분위 응답 시간은 어떻게 되나?
- 이 서비스는 지난 5분 동안 평균 초당 몇 개의 질의를 처리했나?
- 사용자가 우리 사이트에서 시간을 얼마나 보냈나?
- 이 기사가 언제 게시됐나?
- 며칠 몇 시에 미리 알림 이메일을 보내야 하나?
- 이 캐시 항목은 언제 만료되나?
- 로그 파일에 남은 이 오류 메시지의 타임스탬프는 무엇인가?
위의 예시 1~4는 지속 시간(요청 ~ 응답 사이의 시간 구간)을 측정하는 반면, 5~8은 시점(이벤트 발생 시각)을 기술한다.
분산 시스템에서는 통신이 즉각적이지 않으므로, 시간을 다루기 까다롭다. 게다가 네트워크에 있는 개별 장비는 자신의 시계를 가지고 있다. 하드웨어 장치로는 quatz crystal ocillator(수정 발진기)로 존재하며, 이 장치는 완벽하지 않아 각 장비마다 자신의 시간이 존재한다.
시간을 어느 정도는 동기화 할 수 있는데, 가장 널리 쓰이는 메커니즘은 Network Time Protocol, NTP(네트워크 시간 프로토콜)로 GPS 수신자 같은 더욱 정확한 시간 출처를 가진 서버 그룹에서 보고한 시간에 따라 컴퓨터 시계를 조정한다.
단조 시계 대 일 기준 시계
일 기준 시계
일 기준 시계는 현재 날짜와 시간을 반환한다. wall-clock time(벽시계 시간)이라고도 한다. 예를 들어 Linux의 gettime(CLOCK_REALTIME)과 Java의 System.currentTimeMillis()는 epoch 이래로 흐른 초 수를 반환한다. 일 기준 시계는 NTP로 동기화되므로, 모든 장비들에서 동일한 의미를 지닌다. 하지만 윤초를 세지 않는 점과, NTP보다 너무 앞서면 강제 리셋되어 과거 시점으로 가기 때문에 경과 시간을 측정하는 데 적합하지 않다. 또한 일 기준 시계는 coarse-grained(매우 거친) 해상도를 가진다.
단조 시계
단조 시계는 타임아웃이나 서비스 응답 시간 같은 지속 시간을 재는 데 적합하다. 예를 들어 Linux의 clock_gettime(CLOCK_MONOTONIC)과 Java의 System.nanoTime()이 있다. 단조 시계라는 의미는 항상 앞으로 흐른다는 사실에서 나왔다. 한 시점에서 단조 시계를 확인한 후, 나중에 시계를 확인하여 나온 두 값의 차이로 시간이 얼마나 지났는지 알 수 있다. 하지만 장비 간의 단조 시계는 동기화되어있지 않으므로, 둘 장비의 단조 시계를 비교하는 것은 의미가 없다. CPU들도 독립적인 단조 시계를 사용한다. 또한 단조 시계는 해상도가 매우 좋다(마이크로초나 그 이하로 측정이 가능하다).
분산 시스템에서 경과 시간을 재는 데 단조 시계를 쓰는 것은 일반적으로 괜찮다. 다른 노드의 시계 사이에 동기화가 돼야 한다는 가정이 없고 측정이 약간 부정확해도 민감하지 않기 때문이다.
시계 동기화와 정확도
단조 시계는 동기화가 필요 없지만 일 기준 시계는 NTP 서버나 다른 외부 시간 출저에 맞춰 설정돼야 유용하다. 유감스럽게도 시계가 정확한 시간을 알려주게 하는 방법은 기대만큼 신뢰성이 있거나 정확하지 않다.
- 컴퓨터의 수정 시계는 drift(드리프트, 더 빠르거나 느려짐)이 생겨 정확하지 않다.
- 컴퓨터 시계와 NTP 서버 시계가 차이가 나면 시간이 강제 리셋되어 과거로 역행할 수도 있다.
- NTP 동기화 도중 막혀 시계 설정이 긴 시간 동안 달라질 수 있으며, 사실 잘 해봐야 네트워크 지연시간 만큼만 좋아질 수 있다. 또한 NTP 서버 자체가 이상이 있어 잘못된 값을 줄 수도 있다.
- 윤초가 발생하면 시간에 대한 가정이 틀어져, 시스템을 고장낼 수도 있다. 이를 해결하기 위한 최선의 방법은 윤초 조정을 하루에 걸쳐서 서서히 수행하여 NTP 서버가 “거짓말을 하게”하는 것일 수도 있다(smearing, 문지름)이라고 부른다.
- 가상 장비에서 VM 간의 전환이 일어날 때 시계가 수십 밀리초 멈출 수 있다. 이렇게 되면 애플리케이션의 시간이 갑자기 뛸 수도 있다.
- 클라이언트와 같은 완전히 제어할 수 없는 장치는 시계를 고의적으로 변경하는 등의 문제로 믿을 수 없다.
만약 시계 정확도가 중요해서 상당한 자원을 투입할 생각이 있다면(트레이딩 펀트처럼 시계가 중요한 곳에서는) 시계 정확도를 매우 높이는 것도 가능하다. 이런 정확도는 GPS 수신기, Precision Time Protocol, PTP(정밀 시간 프로토콜), 세심한 배포 및 모니터링으로 달성할 수 있다. 그러나 상당한 노력과 전문 기술이 필요하며 시계 동기화가 잘못될 수 있는 수많은 방법이 있다.
동기화된 시계에 의존하기
이전에 언급한 것처럼, 소프트웨어는 가끔 발생할 수 있는 결함에 대해 처리할 수 있어야 하며, 이는 시계도 마찬가지다.
하지만 문제는 시계가 잘못된다는 것을 눈치채지 못한다는 것이다. CPU나 장비, 네트워크가 잘못되면 장비가 전혀 동작하지 않을 가능성이 높아서 눈치챌 수 있지만, 시계의 경우 서서히 실제 시간과 차이가 나기 시작해 만약 소프트웨어가 동기화된 시계에 의존한다면 서서히 데이터 손실이 발생할 확률이 있다.
따라서 동기화된 시계가 필요한 소프트웨어를 사용한다면 필수적으로 모든 장비 사이의 시계 차이를 조심스럽게 모니터링해야 한다. 만약 클러스터에서 특정 노드의 시계가 너무 차이난다면, 해당 노드를 죽은 것으로 선언하고 클러스터에서 제거돼야 한다. 이런 모니터링을 통해 더 큰 피해가 발생하기 전에 조치할 수 있다.
이벤트 순서화용 타임스탬프
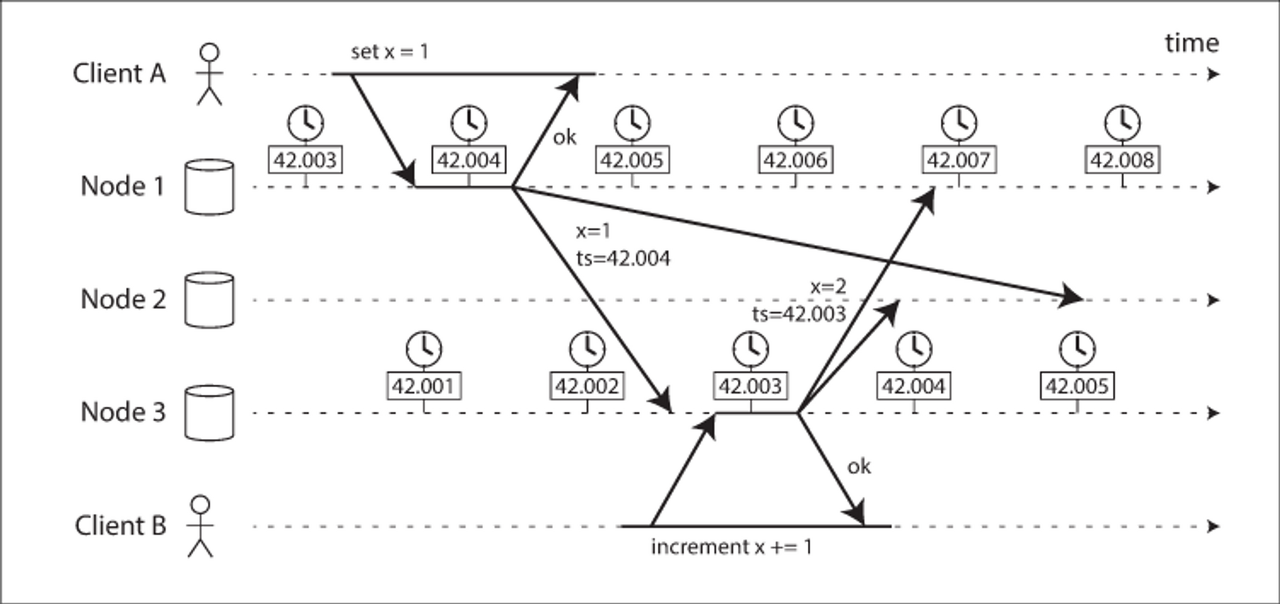
위험한 특정 상황 하나를 고려해 보자. 여러 노드에 걸친 이벤트들의 순서를 정하는 문제다. 위의 예시는 다중 리더 복제에서 일 기준 시간으로 위험하게 사용하는 예를 보여준다. 위 노드들은 3밀리초 미만으로 시계가 잘 동기화돼 있지만, 그럼에도 이벤트 순서가 올바르지 않다. 노드2는 노드1의 이벤트의 시계가 더 나중이기 떄문에 노드3의 이벤트를 버린다. 따라서 클라이언트 B의 증가 연산이 손실된다.
이 충돌 해소 전략은 Last write wins, LWW(최종 쓰기 승리)라고 불리며 다중 리더 복제와, Cassandra, Riak과 같은 리더 없는 데이터베이스에서 널리 사용된다. 타임스탬프를 서버가 아닌 클라이언트에서 생성하는 구현도 있지만 근본적인 문제를 바꾸지는 못한다.
따라서 가장 “최근” 값을 유지하고 다른 것들을 버림으로써 충돌을 해소하고 싶은 유혹이 들더라도 “최근”의 정의는 로컬 일 기준 시계에 의존하며 그 시계는 틀릴 수도 있다는 것을 아는 게 중요하다. NTP로 동기화된 시계를 쓰더라도, 잘못된 순서화가 발생하지 않을 정도로 NTP 동기화를 정확하게 할 수도 없다.
증가하는 카운터를 기반으로 하는 logical clock(논리적 시계)가 이벤트 순서화의 안전한 대안이다. 논리적 시계는 일 기준 시간(physical clock, 물리적 시계)을 측정하지 않고 이벤트의 상대적인 순서를 측정한다.
시계 읽기는 신뢰 구간이 있다
장비의 일 기준 시계를 나노초 해상도로 읽을 수 있다고 해도, 이 값이 정확하다는 의미가 아니다. NTP 서버와 동기화를 진행해도 네트워크, 트리프트로 인해 정밀하지 못하다.
따라서 시계 읽기를 어떤 시점으로 생각하는 대신, 어떤 신뢰 구간에 속하는 시간의 범위로 읽는 게 나을 것이다. 예를 들어 시스템의 현재 시간이 해당 분의 10.3초와 10.5초 사이에 있다고 95% 확신한다는 것이다. 불확실성 경계는 시간 출처(GPS, 원자시계)와 동기화한 시간 이후로 예상되는 시게 드리프트 + NTP 서버의 불확실성 + 네트워크 왕복시간을 더한 값을 기반으로 할 수 있다.
불행하게도 대부분의 시스템(Linux clock_gettime() 등)은 이 불확실성을 노출해주지 않는다. 다만 Spanner에 있는 Google TrueTime API는 로컬 시계의 신뢰 구간을 명시적으로 보고한다. 이 API를 통해 신뢰 구간 타임스탬프 범위 중 [earliest, latest]를 받을 수 있다.
전역 스냅숏용 동기화된 시계
스냅숏 격리는 작고 빠른 읽기 쓰기 트랜잭션과 크고 오래 실행되는 읽기 전용 트랜잭션 모두를 지원해야 하는 데이터베이스에서 아주 유용한 기능이다. 스냅숏 격리는 잠금을 쓰지 않고 읽기 쓰기 트랝개션을 방해하지 않으면서 읽기 전용 트랜잭션이 특정 시점의 일관적인 상태에 있는 데이터베이스를 볼 수 있게 한다.
스냅숏 격리 구현은 단조 증가하는 트랜잭션 ID가 필요한데, 쓰기 트랜잭션 ID가 스냅숏 ID보다 크다면, 그 내용은 읽기 트랜잭션에게 보이지 않는다.
단일 노드 데이터베이스에서는 단순한 카운터로 생성할 수 있지만, 여러 데이터센터에 여러 장비에 분산돼 있을 경우 코디네이션이 필요하므로 전역 단조 증가 트랜잭션 ID를 생성하기 어렵다. 트랜잭션 ID는 스냅숏이 일관성을 가지기 위해 반드시 인과성을 가져야 한다.
동기화가 잘 된 일 기준 시계를 트랜잭션 ID로 쓸 수 없는 이유는 시계 정확도에 관한 불확실성 때문이다. 따라서 Spanner는 다음과 같은 방식으로 스냅숏 격리를 구현한다. 먼저 TrueTime API가 보고한 시계 신뢰 구간을 사용하여 (A = [Aearliest, Alatest]와 B = [Bearliest, Blatest])라는 두 가긴이 겹치지 않는다면(A earliest < A latest < B earliest < B latest), B는 분명히 A보다 나중에 실행됐다고 볼 수 있어 인과성을 명확히 알 수 있다. 이 떄 추가로 Spanner는 읽기 쓰기 트랜잭션을 커밋하기 전에 의도적으로 신뢰 구간의 길이만큼 기다려 신뢰 구간 겹침을 피한다. 이를 통해 타임스탬프의 인과성을 보장한다. 대기 시간을 짧게 하기 위해 신뢰 구간은 최대한 짧게 유지해야 하며, 이런 목적으로 Google은 각 데이터센터에 GPS 수신기나 원자 시계를 배치해서 시계가 약 7 밀리초 이내로 동기화되게 한다.
프로세스 중단
분산 시스템에서 시계를 위험하게 사용하는 다른 예를 생각해보자. 단일 리더 데이터베이스에서, 리더는 다른 노드들로부터 lease(임차권)을 얻어 본인이 알 수 있다. 임차권은 타임아웃이 있는 잠금과 비슷하며, 임차권 획득하면 주기적으로 갱신해야 한다.
이 때 요청 처리 루프를 이런 식으로 만들 수 있다.
while (true) {
request = getIncomingRequest();
// Ensure that the lease always has at least 10 seconds remaining
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000) {
tease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
}이 코드에서 잘못된 점은 무엇일까?
먼저 동기화된 시계에 의존하고 있어, 임차권 만료 시간이 다른 장비에서 설정되었지만 로컬 시스템과 동기화가 깨져있어 코드가 이상한 일을 할 수도 있다.
위의 프로토콜을 로컬 단조로 바꾸더라도 또 다른 문제가 있다. 시간을 확인하는 시점(System.currentTimeMillis())과 요청이 처리되는 시점(process(request)) 사이에 매우 짧은 시간 간격이 있다. 평소에는 코드가 매우 빨리 실행돼서 10초 정도의 버퍼 정도라면 임차권이 만료되지 않게 할 수 있지만, 프로그램 실행 중에 예상치 못한 중단이 생겨 15초 동안 멈춘다면, 임차권이 만료되어 다른 노드가 리더가 됐을 것이고, 기존 리더 노드는 이 사실을 모른 채 안전하지 않은 일을 수행해 버릴 수도 있다.
스레드가 이처럼 아주 오랫동안 멈출 수 있을 다양한 이유가 있다.
- (자바 가상 머신 같은) 여러 프로그래밍 언어 런타임에는 가끔씩 실행 중인 모든 스레드를 멈춰야 하는 Garbage Collector, GC(가비지 컬렉터)가 있다. 이런 “stop-the-world” GC 중단은 때로는 몇 분 동안이나 지속된다고 알려졌다. 핫스팟 JVM의 CMS처럼 이른바 “concurrent(동시적인)” 가비지 컬렉터라도 애플리케이션 코드와 완전히 병렬적으로 실행될 수는 없다. 이들도 때때로 stop-the-world가 필요하다. 이런 중단은 종종 할당 패턴을 바꾸거나 GC 설정을 튜닝해서 줄일 수 있지만 견고한 보장을 제공하려면 최악을 가정해야 한다.
- 가상 환경에서 가상 장비는 suspend(서스펜드, 모든 프로세스 실행을 멈추고 메모리 내용을 디스크에 저장)됐다가 resume(재개, 메모리 내용을 복원하고 실행을 계속)될 수 있다. 이런 중단은 프로세스 실행 중 언제라도 발생할 수 있고 임의의 시간 동안 지속될 수 있다. 이 기능은 때떄로 재부팅 없이 가상 장비를 한 호스트에서 다른 호스트로 live migration(라이브 이전)하는 데 사용되는데, 이 경우 중단 시간의 길이는 프로세스가 메모리에 쓰는 속도에 의존한다.
- 노트북 같은 최종 사용자의 기기에서도 실행이 제멋대로 서스펜드됐다 재개될 수 있다. 예를 들어 사용자가 노트북 덮개를 닫을 때가 있다.
- 운영체제가 다른 스레드도 컨텍스트 스위치하거나 하이퍼바이저가 다른 가상 장비로 스위치되면(가상 장비에서 실행 중일 때) 현재 실행 중인 스레드는 코드의 임의 지점에서 멈출 수 있다. 가상 장비의 경우 다른 가상 장비에서 소비된 CPU 시간은 steal time(스틸 타임)이라고 한다. 장비의 부하가 높으면, 즉 실행 대기 스레드의 큐가 길면 중단된 스레드가 다시 실행되는 데 시간이 좀 걸릴 수도 있다.
- 애플리케이션이 동기식으로 디스크에 접근하면 스레드가 느린 디스크 I/O 연산이 완료되기를 기다리느랴 중단될 수 있다. 여러 언어에서 코드가 명시적으로 파일 접근을 언급하지 않더라도 디스크 접근은 놀랄만큼 일어날 수 있다. 예를 들어 자바 클래스로더는 클래스 파일이 처음 사용될 때 지연 로딩하는데, 이는 프로그램 실행 중 언제라도 일어날 수 있다. 심지어는 I/O 중단과 GC 중간이 공모해서 지연을 결합하기도 한다. 디스크가 실제로는 네트워크 파일시스템이거나 (Amazon의 EBS 같은) 네트워크 블록 장치라면 I/O 지연 시간은 네트워크 지연의 변동성에도 종속적이다.
- 운영체제가 디스크로 스왑(페이징) 할 수 있게 설정됐다면 단순한 메모리 접근만 해도 페이지를 디스크에서 메모리로 로딩하게 하는 페이지 폴트가 발생할 수 있다. 이 느린 I/O 연산이 실행되는 동안 스레드는 멈춘다. 메모리 압박이 높으면 이어서 다른 페이지가 디스크로 스왑될 수 있다. 극단적인 환경에서는 운영체제가 페이지를 메모리 안팎으로 스와핑하느라 대부분의 시간을 쓰고 실제 작업은 거의 못할 수도 있다(이를 thrashing(스래싱)이라고 한다). 이 문제를 피하기 위해 서버 장비에서 페이징은 종종 비활성화된다(스레싱 위험을 무릅쓰느니 프로세스를 죽여서 확보하겠다면).
- 유닉스 프로세스는 SIGSTOP 신호를 보내서 멈출 수 있다. 예를 들어 셸에서 Ctrl + Z 키를 누르면 된다. 이 신호는 프로세스가 SIGCONT 신호로 재개되어 중단됐던 지점에서 다시 실행될 때까지 CPU 사이클을 더 이상 할당받지 못하게 한다. 여러분의 환경에서 보통 SIGSTO을 쓰지 않더라도 운영 엔지니어가 실수로 그 신호를 보낼 수도 있다.
이런 경우가 발생하면 실행 중인 스레드를 어떤 시점에 preempt(선점)하고 얼마간의 시간이 흐른 후 재개할 수 있다. 선점된 스레드는 이를 알아채지 못한다. 이 문제는 단일 장비에서 다중 스레드 코드를 thread-safe(스레드 안전)하게 만드는 것과 비슷하다.
단일 장비에서 다중 스레드 코드를 작성할 때 그 코드를 스레드 안전하게 만들 수 있는 상당히 좋은 도구가 있다. mutex(뮤텍스), semaphore(세마포어), atomic counter(원자적 카운터), lock-free(잠금 없는) 자료구조, blocking queue(블로킹 큐) 등이다. 하지만 이런 도구들은 분산 시스템용으로 바로 변형할 수 엇ㅂ다. 분산 시스템은 공유 메모리가 없고 단지 신뢰성 없는 네트워크를 통해서만 메시지를 보낼 수 있기 때문이다.
분산 시스템에서 노드는 어느 시점에 실행히 상당한 시간 동안 멈출 수 있다고 가정해야 한다. 이 동안 외부 세계는 계속 작동하며, 해당 노드가 응답하지 않으니 죽었다고 선언할 수도 있다. 나중에 노드가 살아나도, 시계를 확인할 때가지 잠들었다는 것을 알아채지 못한다.
응답 시간 보장
앞에서 설명한 바와 같이 많은 프로그래밍 언어와 운영체제에서 스레드와 프로세스는 기약 없는 시간 동안 중단될 수 있다. 이런 현상을 제거할 수 있는 방법이 있기는 하다.
어떤 소프트웨어는 명시된 시간 안에 응답하지 못하면 심각한 손상을 유발하는 환경에서 실행된다(항공기, 자동차, 등). 이러한 시스템에서는 소프트웨어가 응답해야 하는 deadline(데드라인)이 명시된다. 데드라인을 지키지 못하면 전체 시스템의 장애를 유발할 수 있다. 이를 hard real-time(엄격한 실시간 시스템)이라고 한다.
시스템에서 실시간 보장을 제공하려면 소프트웨어 스택의 모든 수준에서 지원이 필요하다. 프로세스는 명시된 간격의 CPU 시간을 할당받을 수 있게 보장되도록 스케줄링해 주는 real-time operating system, RTOS(실시간 운영체제)가 필요하며, 라이브러리 함수는 최악의 수행 시간을 명시하고, 동작 할당이 제한되며, 막대한 양의 테스트와 측정을 해야 한다.
이 떄문에 실시간 시스템은 비용이 많이 들고, 안전이 필수적인 임베디드 장치에서 사용된다. 실시간 시스템은 또한 제 때에 응답해야 하므로 처리량이 더 낮을 수도 있다. 따라서 대부분의 서버측 데이터 처리 시스템에서 실시간 보장은 전혀 경제적이지도, 적절하지도 않다.
가비지 컬렉션의 영향을 제한하기
프로세스 중단의 부정적 영향은 비용이 큰 실시간 스케줄링 보장에 기대지 않고도 카비지 컬렉션의 조정을 통해 완화시킬 수 있다. 언어 런타임은 객체 할당률과 시간에 따라 남아 있는 여유 메모리 공간을 추적할 수 있으므로 언제 가비지 컬렉션을 조정할 수 있다.
최근에 나온 아이디어 하나는 노드가 계획적으로, 잠시 동안 요청 처리를 중단한 후 GC를 실행하고, 그 동안 다른 노드들이 요청을 처리하게 하는 것이다. 이런 트릭은 GC 중단을 클라이언트라부터 감추고, 응답 시간의 상위 백분위를 줄여준다. 지연 시간에 민감한 금융 거래 시스템 중에 이 방법을 쓰는 것도 있다.
아 아이디어의 변종은 컬렉션을 빨리 할 수 있는 수명이 짧은 객체만 가비지 컬렉터를 사용하고, 수명이 긴 객체의 전체 GC가 필요할 만큼 객체가 쌓이기 전에 주기적으로 프로세스를 재시작하는 방법이다. 순회식 업그레이드와 같이 노드 트래픽을 옮긴 후, 순차적으로 재시작할 수 있다.
이러한 조치들이 가비지 컬렉션 중단을 완전히 막을 수는 없지만 애플리케이션에 미치는 영향은 유용하게 줄일 수 있다.
지식, 진실, 그리고 거짓말
이번 장에서는 지금까지 분산 시스템이 단일 컴퓨터에서 프로그램을 실행하는 것과 어떻게 다른지 살펴봤다. 분산 시스템에는 공유 메모리가 없고 지연 변동이 큰 신뢰할 수 없는 네트워크를 통해 메시지를 보낼 수 있을 뿐이며 부분 장애, 신뢰성 없는 시계, 프로세스 중단에 시달릴 수 있다.
분산 시스템에서 네트워크에 있는 노드는 어떤 것도 확실히 알지 못한다. 네트워크를 통해 받은 메시지를 통해 추측할 뿐이다. 이러한 시스템에서 어떤 것이 진실인지 알기 위해서는, 우리는 동작(시스템 모델)에 관해 정한 가정을 명시하고, 이런 가정을 만족시키는 방식(알고리즘)으로 실제 시스템을 설계할 수 있다. 이로써 기반 시스템 모델이 매우 적은 보장만 제공하더라도 신뢰성 있는 동작을 달성할 수 있다.
하지만 이는 간단하지 않다. 이번 장의 나머지 부분에서 분산 시스템의 지식과 진실에 관한 개념을 더 살펴본다.
진실은 다수결로 결정된다
비대칭적인 결함이 있는 네트워크를 가정해보자. 노드는 자신에게 보내지는 요청은 잘 처리하지만, 응답은 유실되버린다. 이 상황에서 노드는 자신이 살아있다고 믿겠지만, 다른 노드들은 응답이 오지 않아 죽었다고 판단할 것이다. 또한 GC 때문에 노드가 멈추는 경우에도, 해당 노드가 다시 작동할 때는 시간이 흐른 것 같지 않지만, 다른 노드들은 이미 해당 노드가 죽었다고 판단할 것이다.
이 이야기의 교훈은 노드가 상황에 대한 자신의 판단을 반드시 믿을 수 있는 것은 아니라는 것이다. 분산 시스템은 한 노드에만 의존할 수는 없다. 노드에 언제든 장애가 나서 잠쟂적으로 시스템이 멈추고 복구할 수 없게 될 수도 있기 때문이다.
대신 여러 분산 알고리즘은 quorum(정족수), 즉 노드들 사이의 투표를 통해 어떠한 사항을 결정한다. 이러한 결정에 따라 어떠한 노드가 죽었다고 선언되었다면, 해당 노드는 결정에 따라 물러나야 한다. 보통 노드의 과반수 이상을 정족수로 삼는 게 가장 흔하다. 과반수 정족수를 사용하면 개별 노드들에 장애가 나더라도 시스템이 계속 동작할 수 있기 때문이다.
리더와 잠금
시스템이 오직 하나의 뭔가가 필요할 때가 자주 있다. 예를 들어
- 스플릿 브레인을 피하기 위해 오직 한 노드만 데이터베이스 파티션의 리더가 될 수 있다.
- 특정한 자원이나 객체에 동시에 쓰거나 오염시키는 것을 방지하기 위해 오직 하나의 트랜잭션이나 클라이언트만 어떤 자원이나 객체의 잠금을 획득할 수 있다.
- 사용자명으로 사용자를 유일하게 식별할 수 있어야 하므로 오직 한 명의 사용자만 특정한 사용자명으로 등록할 수 있다.
분산 시스템에서 이를 구현하려면 주의해야 한다. 어떤 노드가 스스로를 “선택된 자”라고 믿을지라도, 노드의 정족수가 반드시 동의하는 것이 아닐 수도 있기 때문이다(네트워크 문제나 GC 문제 때문에). 만약 노드가 본인이 계속 “선택된” 자인 것처럼 행동한다면 이를 고려하지 못한 시스템에서는 문제가 발생할 수 있다.
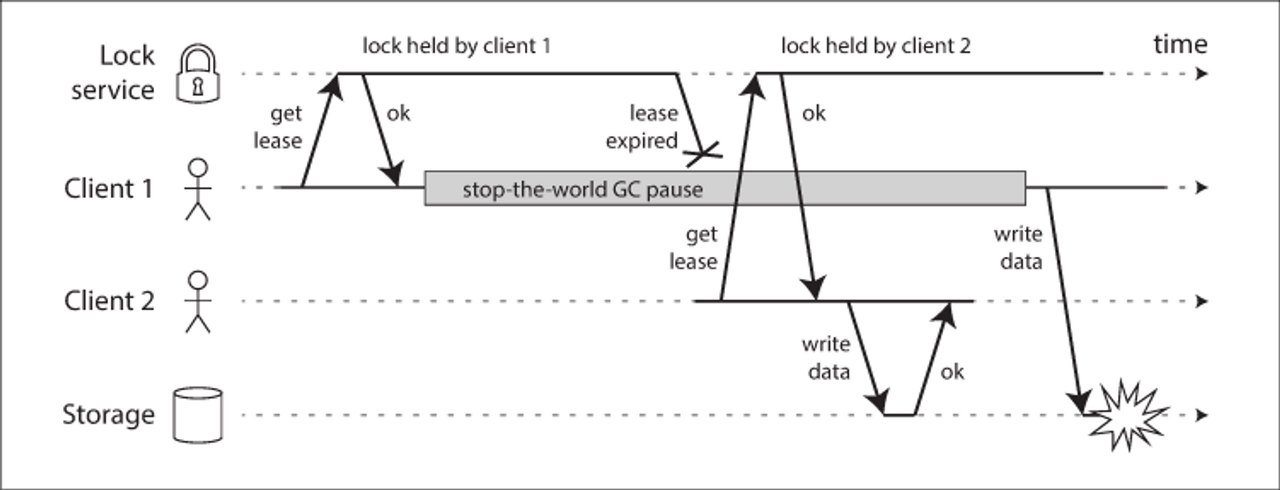
예를 들어 위의 예시는 잠금을 잘못 구현해서 생긴 데이터 오염 버그를 보여준다(HBase에서 이 문제가 있었다). 저장 서비스에 있는 어떤 파일을 한 번에 한 클라이언트만이 접근하도록 보장하기 위해, 임차권을 통해 기능을 구현했다.
문제는 프로세스 중단에서 언급한 바와 같이 임차권을 가진 클라이언트가 너무 오래 멈춰 있으면 해당 임차권이 만료되고, 다른 클라이언트가 임차권을 얻게 된다. 멈췄던 클라이언트가 되돌아왔을 때 해당 클라이언트는 여전히 유요한 임차권을 갖고 있는 것으로 잘못 알고 파일에 쓴다. 그 결과 클라이언트들의 쓰기가 충돌되고 파일이 오염된다.
펜싱 토큰
이 상황을 방지하기 위해, 잠금이나 임차권을 쓸 때, 자신이 “선택된 자”라고 잘못 믿고 있는 노드가 나머지 시스템을 방해할 수 없도록 보장해야 한다. 이 목적을 달성하는 상당히 단순한 기법으로 fencing(펜싱)이 있다.
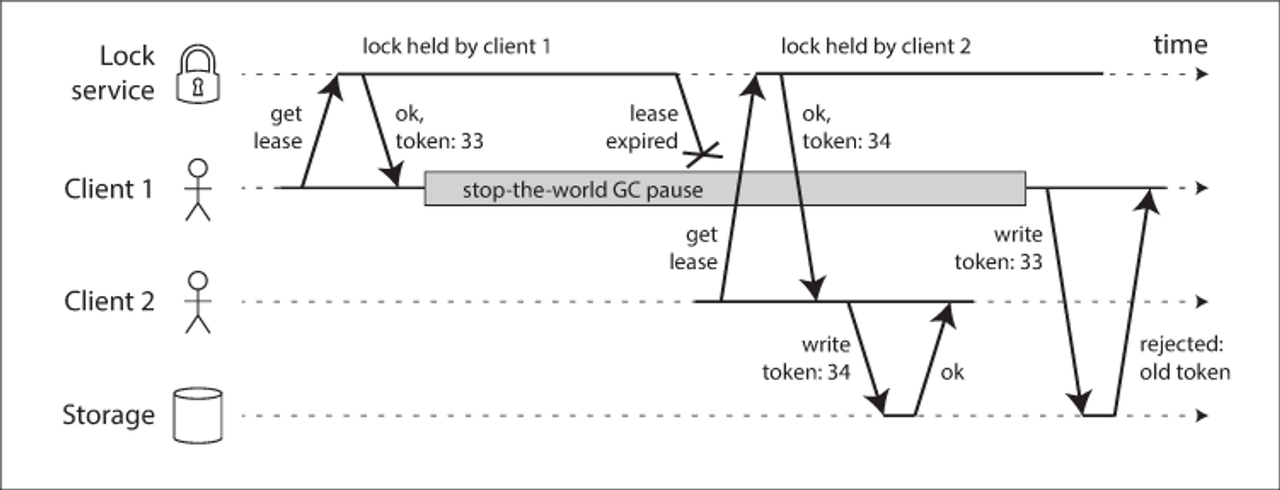
잠금 서버가 잠금이나 임차권을 승인할 때마다 fencing token(펜싱 토큰)도 반환한다고 가정한다. 펜싱 토큰은 잠금이 승인될 때마다 증가하는 숫자다. 그러면 클라이언트가 쓰기 요청을 저장소 서비스로 보낼 때마다 자신의 현재 펜싱 토큰을 포함하도록 요구할 수 있다.
위의 예시에서는 클라이언트 1이 33번 토큰으로 임차권을 획득했지만 오랫동안 중단되어 임차권을 잃었고, 클라이언트 2는 34번 토큰으로 임차권을 얻은 후, 저장소 서비스로 34번 토큰을 포함한 쓰기 요청을 보낸다. 이후 클라이언트 1이 되살아나서 33번 토큰을 포함한 쓰기 요청을 보내도 저장소 서버는 토큰 번호 34 쓰기를 처리했으므로, 이보다 작은 쓰기를 거부한다.
잠금 서비스로 Zookeeper를 사용하면 트랜잭션 ID zxid나 노드 버전 cversion을 펜싱 토큰으로 사용할 수 있다. 이들은 단조 증가가 보장되므로 필요한 속성을 지닌다.
이 메커니즘은 토큰을 활동하는 활동적인 역할을 맡아야 한다. 서버 측에서 이렇게 토큰을 확인하는 것은 결점으로 보이지만 좋은 방법이다. 클라이언트들에게서 어떠한 “폭력적인” 요청이 올지 모르므로, 서버 측에서 토큰을 확인하여 보호하는 것이 좋다.
비잔틴 결함
펜싱 토큰은 부주의(노드가 본인의 임차권이 만료됐다는 것을 모름)에 의한 오류에 빠진 노드를 감지하고 차단할 수 있다. 이러한 가정은 노드들이 신뢰성은 없지만 정직하다고 가정한다.
하지만 노드들이 “거짓말”(임의의 결함이 있거나 오염된 응답을 보냄)을 할지도 모른다. 분산 시스템 문제는 이러한 위험이 있다면 훨씬 더 어려워진다. 이런 동작은 Byzantine fault(비잔틴 결함)이라고 하며, 이렇게 신뢰할 수 없는 환경에서 합의에 도달하는 문제를 Byzantine Generals Problem(비잔틴 장군 문제, 두 장군 문제를 일반화한 문제. n명의 장군이 동의해야 하는 합의에서 전령으로만 대화할 수 있다. 하지만 전령들은 늦거나 실종될 수 있으며, 장군들 중에서는 배신자들이 존재하여 합의를 혼란스럽게 할 수도 있다)라고 한다.
일부 노드가 오장독하고 프로토콜을 준수하지 않거나 악의적인 공격자가 네트워크를 방해하더라도 시스템이 계속 올바르게 동작한다면 이 시스템은 Byzantine fault-tolerant(비잔틴 내결함성을 지닌다). 이런 관심사는 어떤 특정 환경에서 유의미하다. 예를 들어
- 항공우주 산업 환경에서 컴퓨터의 메모리나 CPU 레지스터에 저장된 데이터는 방사선에 오염돼서 그 컴퓨터가 다른 노드에게 전혀 예측할 수 없는 방식으로 반응할 수 있다. 시스템 장애는 매우 비용이 크므로(항공기 사고로 모든 사람이 죽을 수 있음) 비행 제어 시스템은 비잔틴 결함을 견딜 수 있어야 한다.
- 여러 조직이 참여하는 시스템에서 어떤 참여자들은 다른 사람을 속이거나 사취하려 할지도 모른다. 이런 호나경에서는 노드가 다른 노드의 메시지를 그냥 믿는 것은 안전하지 않다. 메시지가 악의를 가지고 보내졌을 수 있기 때문이다. 이를테면 서로 신뢰할 수 없는 단체들이 중앙 권한에 기대지 않고 트랜잭션이 발생했는지 아닌지를 판단하는 방법으로 Bitcoin(비트코인)이나 다른 블록체인 같은 P2P 네트워크를 고려할 수 있다.
그러나 이 책에서 살펴보는 시스템의 종류는 보통 비잔틴 결함이 없다고 가정할 수 있다(보통은 데이터센터의 모든 노드를 제어할 수 잇고, 방사선 수준은 메모리 오염이 큰 문제가 안 될 정도로 낮음). 또한 시스템이 비잔틴 내결함성을 지니도록 만드는 프로토콜은 복잡하며 특정 하드웨어 수준의 지원에 의존하다. 대부분의 서버 측 데이터 시스템에서 비잔틴 내결함성 솔루션을 배치하는 것은 비용이 커서 실용적이지 않다.
웹 애플리케이션은 최종 사용자가 제어하는 웹브라우저 같은 클라이언트의 행동이 임의적이고 악의적이라고 예상해야 한다. 이는 input validation(입력 확인), sanitization(살균), output escaping(출력 이스케이핑)이 매우 중요한 이유다. 예를 들어 SQL injection(SQL 주입 공격)과 cross site scripting(크로스 사이트 스크립팅)을 막아야 한다. 하지만 비잔틴 내결함성 프로토콜은 여기서 쓰지는 않고, 클라이언트의 이러한 행동이 허용됐는지는 결정하는 권한을 서버에게 줄 뿐이다. 비잔틴 내결함성은 이런 중앙 권한이 없는 P2P 네트워크에 더 적절하다
또한 비잔틴 내결함성 알고리즘에서는 서로 다른 노드(소프트웨어) n개에서 2/3 이상의 노드가 올바르게 동작하기를 바라므로, 동일한 소프트웨어를 모든 노드에 배포하는 방식에서는 사용할 수 없다. 같은 이유로 공격자가 노드 하나를 침해할 수 있다면 모든 노드를 침해할 수도 있기 때문에, 비잔틴 프로토콜로 공격을 보호할 수는 없다. 따라서 전통적인 방어 메커니즘(인증, 접근 제어, 암호화, 방화벽 등)이 여전히 공격자로부터 보호하는 주요 수단으로 사용되고 있다.
약한 형태의 거짓말
노드들로부터의 약한 형태의 “거짓말”을 보호해주는 메커니즘을 소프트웨어에 추가하는 게 가치가 있을 수 있다. 이것이 완전한 비잔틴 내결함성을 지니지는 않지만 그럼에도 더욱 나은 신뢰성으로 향하는 간단하고 실용적인 발걸음이다. 예를 들면
- 네트워크 패킷은 때떄로 하드웨어 문제나 운영체제, 드라이버, 라우터 등의 버그 때문에 오염된다. 보통 오염된 패킷은 TCP와 UDP에 내장된 체크섬으로 검출되지만 때로는 검출을 피하는 경우도 있다. 이런 오염으로부터 보호하려면 보통 애플리케이션 수준 프로토콜에서 체크섬을 쓰는 것처럼 단순한 수단을 쓰면 충분하다.
- 공개적으로 접근 가능한 애플리케이션은 사용자 입력을 신중하게 살균해야 한다. 예를 들어 값이 합당한 범위에 속하는지 확인하고, 메모리를 대량으로 할당해서 서비스 거부가 발생하지 않도록 문자열의 크기를 제한해야 한다. 방화벽 뒤에 있는 내부 서비스는 입력 확인을 덜 엄격하게 할 수도 있겠지만 입력값에 대해 기본적인 sanity-checking(정상성 점검)을 하는 게 좋다.
- NTP 클라이언트는 여러 서버 주소를 설정할 수 있다. 동기화를 할 때 클라이언트는 모든 서버에 접속해서 그들의 오차를 추정한 후 서버 중 다수가 어떤 시간 범위에 동의하는지 확인할 수 있다. 대다수의 서버들이 정상이기만 하면 잘못된 시간을 보고하는 잘못 설정된 NTP 서버를 outlier(이상치)로 검출해서 동기화 대상에서 제거할 수 있다. NTP에 여러 서버를 사용하면 서버 한 대를 쓸 때보다 견고해진다.
시스템 모델과 현실
분산 시스템 문제를 해결하기 위해 많은 알고리즘이 설계되고 있다. 이러한 알고리즘들이 유용하려면 이번 장에서 설명한 분산 시스템의 다양한 결함을 견딜 수 있어야 한다.
알고리즘은 그들이 실행되는 하드웨어와 소프트웨어에 심하게 의존하지 않는 방식으로 작성해야 한다. 이를 위해서는 시스템에서 발생할 수 있는 결함의 종류를 정형화해야 하는데, 이를 system model(시스템 모델)이라고 한다.
타이밍 가정에 대해서는 세 가지 시스템 모델이 흔히 사용된다.
- 동기식 모델: 네트워크 지연, 프로세스 중단, 시계 오차에 모두 제한이 있다고 가정한다. 즉, 이들이 어떤 고정된 상한치를 초과하지 않는다는 의미이다. 기약 없는 지연과 중단이 발생하기 때문에, 동기식 모델은 현실 시스템 대부분에서 현실적인 모델이 아니다.
- 부분 동기식 모델: 시스템이 대부분의 시간에는 동기식 시스템처럼 동작하지만, 때떄로 네트워크 지연, 프로세스 중단, 시계 드리프트의 한계치를 초과한다는 뜻이다. 이것은 많은 시스템에서 현실적인 모델이다.
- 비동기식 모델: 이 모델에서 알고리즘은 타이밍에 대한 어떤 가정도 할 수 없다. 심지어는 시계가 없어 타임아웃 등을 쓸 수 없을 수도 있다. 이러한 상황에서 알고리즘은 매우 제한적이게 된다.
노드 장애에 관한 세 가지 시스템 모델은 다음과 같다.
- crash-stop(죽으면 중단하는) 결함: 알고리즘은 노드에 장애가 나면, 죽었다고 가정한다. 노드가 응답을하지 않으면 다시는 사용할 수 없다.
- crash-recovery(죽으면 복구하는) 결함: 노드가 어느 순간에 죽을 수 있지만 알려지지 않은 시간이 흐른 후에는 아마도 다시 응답하기 시작할 것이라고 가정한다. 죽으면 복구하는 모델에서 노드는 메모리에 있는 상태는 손실되지만 죽어도 데이터가 남아 있는 안정된 저장소가 있다고 가정한다.
- 비잔틴(임의적인) 결함: 노드는 다른 노드를 속이거나 기만하는 것을 포함해 전적으로 무슨 일이든 할 수 있다.
현실 시스템을 모델링하는 데는 죽으면 복구하는 결함을 지닌, 부분 동기식 모델이 일반적으로 가장 유용한 모델이다. 그러면 분산 알고리즘은 이 모델에 어떻게 대응할 수 있을까?
알고리즘의 정확성
알고리즘이 correct(정확하다)는 게 어떤 의미인지 정의하기 위해 알고리즘의 property(속성)을 기술할 수 있다. 예를 펜싱 토큰 알고리즘은 다음 속성을 지녀야 한다.
- 유일성: 펜싱 토큰 요청이 같은 값을 반환하지 않는다.
- 단조 일련번호: 요청 x가 토큰 tx를, 요청 y가 토큰 ty를 반환했고 y가 시작하기 전에 x가 완료됐다면, tx < ty를 만족한다.
- 가용성: 펜싱 토큰을 요청하고 죽지 않은 노드는 결국에는 응답을 받는다.
알고리즘은 시스템 모델에서 발생하리라고 가정한 모든 상황에서 그 속성들을 항상 만족시키면 해당 시스템 모델에서 정확하다. 그러나 모든 노드가 죽거나 네트워크가 끊기면 어떤 알고리즘은 아무것도 할 수 없다.
안전성과 활동성
이를 위해 두 가지 다른 종류의 속성, safety(안전성)과 liveness(활동성)을 구별할 필요가 있다. 앞에 예에서 유일성과 단조 일련번호는 안전성 속성이지만 가용성은 활동성 속성이다.
안전성은 흔히 비공식적으로 나쁜 일은 일어나지 않는다라고, 활동성은 좋은 일은 결국(eventual consistency) 일어난다라고 정의된다. 이들의 실제 정의는 정확하고 수학적이다.
- 안전성 속성이 위반되면 그 속성이 깨진 특정 시점을 가리킬 수 있다(중복된 펜싱 토큰을 반환한 특정 연산을 식별할 수 있다). 안전성 속성이 위반된 후에는 그 위반을 취소할 수 없다. 이미 손상된 상태다.
- 활동성 속성은 반대로 동작한다. 어떤 시점을 정하지 못할 수 있지만(노드의 응답을 받지 못했음), 항상 미래에 그 속성을 만족시킬 수 있다(응답을 받을 수 있다)는 희망이 있다
안정성과 활동성 속성을 구별하면 어려운 시스템 모델을 다루는 데 도움이 된다. 분산 알고리즘은 시스템 모델의 모든 상황에서 안전성 속성이 항상 만족되기를 요구하는 게 일반적이다. 즉 모든 노드가 죽거나 네트워크 전체에 장애가 생기더라도 알고리즘은 잘못된 결과를 반환하지 않는다고 보장해야 한다.
그러나 활동성 속성에 대해서는 경고를 하는 게 허용된다. 예를 들어 노드의 다수가 죽지 않고 네트워크가 중단으로부터 결국 복구됐을 때만 요청이 응답을 받아야 한다고 말할 수 있다. 부분 동기식 시스템 모델의 정의는 시스템이 결국 동기식 상태로 돌아오기를, 즉 얼마간의 네트워크 끊김이 있다면 단지 한정된 기간 동안만 지속된 후 복구되기를 요구한다.
시스템 모델을 현실 세계에 대응시키기
안정성 및 활동성 속성과 시스템 모델은 분산 시스템의 정확성을 따져보는 데 매우 유용하다. 그러나 현업에서 알고리즘을 구현할 때 현실의 지저분한 사실들이 여러분을 곤란하게 만들고 시스템 모델은 현실의 단순화된 추상화라는 게 명백해진다.
이를테면 죽으면 복구하는 모델에서, 노드의 디스크 데이터가 오염되거나 지워지는 경우가 발생하면 알고리즘은 제대로 작동할 수 없다. 정족수 알고리즘은 노드가 저장한 데이터를 기억하고 있다는 것에 의존하는데, 이 경우 정족수 조건이 깨지게 되며, 알고리즘의 정확성도 깨뜨리게 된다. 노드의 데이터가 손실될 수 있는 새로운 시스템 모델이 필요할 수도 있지만, 이런 모델은 따져보기 힘들다.
알고리즘을 이론적으로 설명할 때는 그냥 어떤 일이 일어나지 않는다고 가정할 수 있다. 그리고 non-Byzantine(비-비잔틴) 시스템에서는 일어날 수 있는 결함과 일어날 수 없는 결함에 대해 어떤 가정을 해야 한다. 그러나 실제 구현에는 여전히 불가능하다고 가정했던 일이 발생하는 경우를 처리하는 코드를 포함시켜야 할 수도 있다.
그렇다고 해서 이론적인 추상 시스템 모델이 쓸모없다는 것은 아니다. 추상 시스템 모델은 현실 시스템의 복잡함에서 우리가 추론할 수 있는 관리 가능한 결함의 집합을 뽑아내서, 문제를 이해하고 체계적으로 해결하려고 노력할 수 있게 하는 데 엄청난 도움이 된다. 어떤 시스템 모델에서 그것들의 속성이 항상 성립한다고 보여줌으로써 알고리즘이 올바르다고 증명할 수 있다.
알고리즘이 올바르게 증명됐더라도 반드시 현실 시스템에서의 구현의 언제나 올바르게 동작하는 뜻은 아니다. 그렇지만 알고리즘의 증명은 아주 좋은 첫걸음이다. 이론적 분석은 실제 시스템에서 흔치 않은 상황이 발생하여 가정이 깨질 때만 발생하는 알고리즘의 문제를 들드러낼 수 있기 때문이다. 이론적 분석과 경험적 실험은 똑같이 중요하다.
정리
partial failure(부분 실패)가 생길 수 있다는 사실은 분산 시스템의 뚜렷한 특성이다. 소프트웨어가 다른 노드와 연관된 뭔가를 하려고 할 때는 언제나 가끔씩 실패하거나 임의로 느려지거나 전혀 응답하지 않을 가능성이 있다. 따라서 분산 시스템에서 우리는 구성 요소의 일부가 고장 나더라도 전체로서의 시스템은 계속 동작할 수 있도록 부분 실패에 대한 내성(fault tolerant)을 소프트웨어에 내장하려고 노력한다.
결함을 견뎌내려면 그것을 감지하는 것이 첫걸음이지만 그것조차 어렵다. 대부분의 시스템은 노드에 장애가 발생했는지 알 수 있는 정확한 메커니즘이 없어서 대부분의 분산 알고리즘은 원격 노드를 아직 쓸 수 있는지 결정하기 위해 타임아웃을 사용한다. 그러나 타임아웃은 네트워크 장애와 노드 장애를 구별할 수 없고 변동이 큰 네트워크 지연 때문에 때때로 노드가 죽은 것으로 잘못 의심받을 수 있다. 게다가 때로는 노드가 성능이 저하된 상태일 수도 있다.
결함이 발견됐을 때 시스템이 이를 견딜 수 있게 만들기도 쉽지 않다. 장비들 사이에는 전역변수도, 공유 메모리도, 공통된 지식이나 어떤 종류의 공유 상태도 없다. 노드들은 심지어 몇 시인지조차 동의하지 못한다. 노드들 사이에서 정보가 흐를 수 있는 유일한 방법은 신뢰성이 없는 네트워크로 보내는 것뿐이다. 단일 노드가 안전하게 중대한 결정을 할 수 없으므로 다른 노드의 도움을 요청하고 동의할 정족수를 이루려고 시도하는 프로토콜이 필요하다.
동일한 연산은 항상 결정적으로 동일한 결과를 반환하는, 단일 컴퓨터의 이상적인 수학적 완전함 안에서 소프트웨어를 작성하는 데 익숙하다면 분산 시스템의 지저분한 몰리적 현실로의 이동은 약간 충격적일 수 있다. 반대로 분산 시스템 엔지니어들은 종종 단일 컴퓨터에서 해결할 수 있는 문제를 사소한 것으로 간주한다. 하지만 단일 컴퓨터로도 많은 일을 할 수 있으며, 단일 컴퓨터로 잘 할 수 있다면 일반적으로 그렇게 할 가치가 있다.
그러나 2부 소개에서 설명한 것처럼 분산 시스템을 원하는 이유에는 확장성만 있는 게 아니다. 내결함성과 짧은 지연 시간도 똑같이 중요한 목적이며 이들은 단일 노드로는 달성할 수 없다.
이번 장에서는 분산 시스템에서 나타날 수 있는 광범위한 문제를 설명했다. 몇 가지를 뽑아보면
- 네트워크 결함: 네트워크로 패킷을 보내려고 할 때는 언제나 패킷이 손실되거나 임의대로 지연될 수 있다. 마찬가지로 응답도 손실되거나 지연될 수 있으므로 응답을 받지 못하면 메시지가 전달됐는지 아닌지를 알 수 없다.
- 시계 결함: 노드의 시계는 다른 노드와 심하게 맞지 않을 수 있고, 시간이 갑자기 앞뒤로 뛸 수도 있다. 그리고 시계의 오차 구간을 측정할 좋은 수단이 없을 가능성이 크므로 시계에 의존하는 것은 위험하다.
- 프로세스 결함: 프로세스는 실행 도중 어느 시점에서(stop-the-world GC 등으로) 상당한 시간 동안 멈출 수 있고, 다른 노드에 의해 죽었다고 선언될 수 있으며 되살아났을 때 멈췄다는 사실을 알지 못할 수도 있다.
이러한 결함을 지닌 네트워크, 시계, 프로세스가 신뢰성이 없는 게 불가피한 자연 법칙인지도 살펴봤다. 그렇지 않다는 것을 알았다. 엄격한 실시간 응답 보장과 네트워크 지연에 제한을 두는 것은 가능하지만 그렇게 하는 비용이 매우 크며 하드웨어 자원 사용률이 낮아진다. 대다수의 안전이 필수적이지 않은 시스템은 비싸고 신뢰성이 있는 것보다 저렴하고 신뢰성이 없는 것을 택한다.
신뢰성 있는 구성 요소를 가정해서 한 구성 요소에 장애가 생기면 전체를 멈췄다 재시작해야 하는 슈퍼컴퓨터도 언급했다. 반대로 분산 시스템은 모든 결함과 유지보수를 노드 수준에서 처리할 수 있으므로 서비스 수준에서는 이론적으로 중단 없이 영원히 실행될 수 있다.
이번 장은 모두 문제에 대한 것이였고 암울한 관점을 보여줬다. 다음 장에서는 해결책으로 옮겨가서 분산 시스템의 모든 문제에 대처하도록 설계된 알고리즘을 살펴본다.
Reference: http://www.yes24.com/Product/Goods/59566585
데이터 중심 애플리케이션 설계 - YES24
데이터는 오늘날 시스템을 설계할 때 마주치는 많은 도전 과제 중에서도 가장 중심에 있다. 확장성, 일관성, 신뢰성, 효율성, 유지보수성과 같은 해결하기 어려운 문제를 파악해야 할 뿐 아니라
www.yes24.com
'백엔드 > 분산 시스템' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] Part 3. 파생 데이터 (0) | 2023.02.26 |
|---|---|
| [데이터 중심 애플리케이션 설계] 09장. 정족수와 합의 (0) | 2023.02.19 |
| [데이터 중심 애플리케이션 설계] 07장. 트랜잭션 (0) | 2023.02.05 |
| [데이터 중심 애플리케이션 설계] 06장. 파티셔닝 (0) | 2023.01.29 |
| [데이터 중심 애플리케이션 설계] Part 1. 데이터 시스템의 기초 (0) | 2023.01.22 |