Part 2. 분산 데이터
데이터셋이 매우 크거나 질의 처리량이 매우 높다면 복제만으로는 부족하고 데이터를 파티션으로 쪼갤 필요가 있다. 이 작업을 샤딩이라고도 한다.
파티션은 보통 각 데이터 단위(레코드, 로우, 문서)로 나누며, 결과적으로 각 파티션은 그 자체로 작은 데이터베이스가 된다.
데이터 파티셔닝을 원하는 주된 이유는 확장성 때문이다. 비공유(shared-nothing) 클러스터에서 파티션은 다른 노드에 저장할 수 있다. 이를 통해 대용량 데이터셋이 여러 디스크에 분산될 수 있고, 질의 부하가 여러 프로세스에 분산될 수 있다. 파티션은 독립적으로 자신의 질의를 처리할 수 있으므로 노드를 추가함으로써 질의 처리량을 늘릴 수 있으며, 복잡한 질의는 여러 노드에서 병렬 실행이 가능하도록 할 수 있다.
파티셔닝 지원 데이터베이스는 1980년대부터 Teradata, Tandem NonStop SQL 등의 제품들로 개척되었고, 최근에는 NoSQL 데이터베이스와 Hadoop 기반 데이터 웨어하우스에서 재발견됐다. 어떤 시스템들은 트랜잭션 작업부하용으로, 어떤 시스템들은 분석용으로 설계됐다. 이 차이는 시스템을 튜닝하는 방법에 영향을 미치지만 파티셔닝의 기본 원칙은 두 종류의 작업부하에 모두 적용된다.
이번 장에서는 먼저 대용량 데이터셋을 파티셔닝하는 몇 가지 방법을 살펴본 후, 데이터 색인과 파티셔닝이 어떻게 상호작용하는지 알아본다. 그 다음에 클러스터에 노드 추가/제거에서 필요한 재균형화에 대해 알아본다. 마지막으로 데이터베이스가 어떻게 요청을 올바른 파티션에 전달하고 질의를 실행하는지 개략적으로 살펴본다.
파티셔닝과 복제
보통 복제와 파티셔닝을 함께 적용해 각 파티션의 복사본을 여러 노드에 저장한다. 각 레코드는 정확히 한 파티션에 속하더라도 이를 여러 다른 노드에 젖아해서 내결함성을 보장할 수 있다는 의미이다.
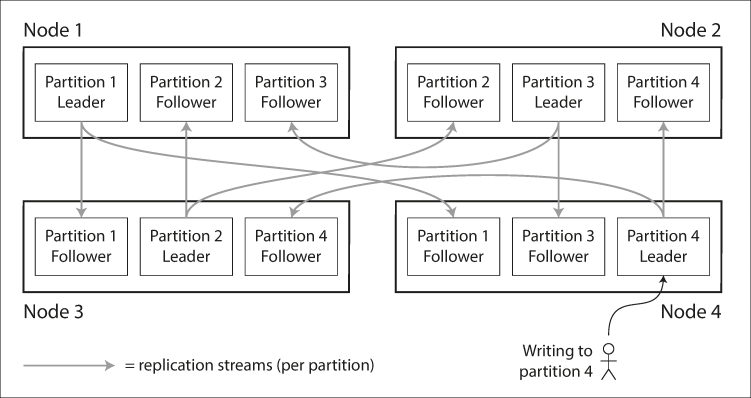
복제와 파티셔닝의 조합은 위와 같다. 여기에 리더 팔로워 복제 모델을 사용한다면 한 노드에 여러 파티션을 저장하고, 각 파티션의 리더가 하나의 노드에 할당되면서 팔로워들은 다른 노드에 할당되는 형태를 띄게 된다. 각 노드는 어떤 파티션에게는 리더이면서 다른 파티션에게는 팔로워가 될 수 있다.
일반적인 복제 파티셔닝 조합에서는 파티셔닝 방식과 복제 방식을 독립적으로 선택한다.
키-값 데이터 파티셔닝
대량의 데이터를 파티셔닝할 때, 어떤 레코드를 어떤노드에 저장할지 어떻게 결정해야 할까?
파티셔닝의 목적은 데이터와 질의 부하를 노드 사이에 고르게 분산시키는 것이다. 모든 노드가 동일한 분량을 담당할 경우 n대의 노드를 사용하면 1대를 사용한 것 보다 이론상 n배의 데이터를 저장하고 10배의 읽기/쓰기 요청을 처리할 수 있다.
하지만 파티셔닝이 고르게 이뤄지지 않아 다른 파티션보다 데이터가 많거나 질의를 많이 받는 파티션이 있다면 해당 파티션은 skewed(쏠렸다)고 말한다. 쏠림이 있으면 파티셔닝의 효과가 매우 떨어진다. 극단적인 경우 모든 부하가 한 파티션에 몰려 해당 노드가 병목이 될 수 있는데, 불균형하게 부하가 높은 파티션을 핫스팟이라고 한다.
핫스팟을 회피하는 가장 단순한 방법은 레코드를 할당할 노드를 무작위로 선택하는 것이다. 그러면 데이터가 매우 고르게 분산되지만 어떤 레코드가 어디에 있는지 모르기 때문에 모든 노드에 병렬적으로 질의를 실행햐 한다는 단점이 있다.
더 좋은 방법은 키-값 데이터 모델을 사용하는 것이다. 키-값 데이터 모델을 사용하면 백과사전에서 알파벳 순으로 정렬된 제목을 찾는 것 처럼, 찾고자 하는 항목을 빨리 찾을 수 있다.
키 범위 기준 파티셔닝
키 범위 기준 파티셔닝에서는 중이 백과사전처럼 각 파티션에 연속된 범위에 키를 할당하는 것이다. 각 범위들 사이의 경계를 알면 어떤 키가 어느 파티션에 속하는지 쉽게 찾을 수 있다. 또 어떤 팥션이 어느 노드에 할당됐는지 알면 적절한 노드로 요청을 직접 보낼 수 있다.
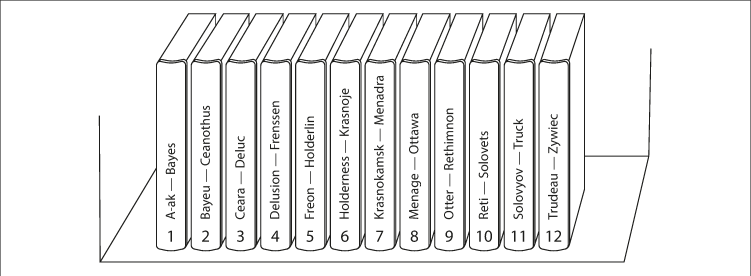
데이터가 고르게 분포하지 않고, 특정 키에 대응하는 데이터가 많을 수 있기 때문에 키 범위를 반드시 동일하게 지정할 필요가 없다. 파티션 경계는 관리자가 수동으로 선택하거나 데이터베이스에서 자동으로 선택되게 할 수 있다. 이런 파티셔닝 전략은 BigTable, HBase, RethinkDB, MongoDB 2.4 이전 버전에서 사용된다.
각 파티션 내에서는 키를 정렬된 순서로 저장할 수 있다(SS 테이블, LSM 트리). 이렇게 하면 범위 스캔이 쉬워지는 이점이 있고, 키를 연쇄된 색인으로 간주해서 질의 하나로 관련 레코드 여러 개를 읽어오는 데 사용할 수 있다(다중 칼럼 색인).
하지만 키 범위 기준 타피셔닝은 특정한 접근 패턴이 핫스팟을 유발하는 단점이 있다. 예를 들어 특정 날짜의 데이터를 파티션 하나가 담당하는 경우, 해당 날에 모든 쓰기 연산은 해당 파티션으로 전달되어 해당 파티션만 과부화가 걸리고 나머지 파티션은 유휴 상태로 남아 있을 수 있다. 이를 회피하려면 키를 다양한 조합의 형태로 만들어 사용해야 한다. 예를 들어 특정 타임스탬프만 사용하는 것이 아닌, 앞에 쓰기 연산을 수행하는 매체의 추가적인 정보들을 다는 형식이다.
키의 해시값 기준 파티셔닝
쏠림과 핫스팟의 위험 때문에 많은 분산 데이터스토어는 키의 파티션을 정하는 데 해시 함수를 사용한다.
좋은 해시 함수는 쏠린 데이터를 입력으로 받아 균일하게 분산되게 한다. 또한 파티셔닝용 해시 함수는 암호적으로 강력할 필요가 없다. 예를 들어 Cassandra와 MongoDB는 MD5를 쓰고, Voldemort는 Fowler-Noll-Vo를 사용한다. 다만 프로그래밍 언어에 해시 테이블 용의 내장된 간단한 해시 함수들은 파티셔닝에는 적합하지 않을 수도 있다. 예를 들어 Java의 Object.hascode()와 Ruby의 Object#hash는 같은 키를 넣어도 다른 프로세스에서는 다른 해시값을 반환할 수 있다.

키에 적합 해시 함수를 구했다면 위 그림처럼 각 파티션에 키 범위 대신 해시값 범위를 할당하고 해시값이 파티션의 버무이에 속하는 모든 키를 그 파티션에 할당하면 된다. 이 기법은 키를 파티션 사이에 균일하게 분산시키는 데 좋다. 파티션 경계는크기가 동일하도록 나눌 수도 있고 무작위에 가깝게 선택할 수도 있다. 이런 기법을 일관성 해싱이라고 부르기도한다.
하지만 키의 해시값 기준 파티셔닝은 키 범위 파티셔닝의 효율적인 범위 질의라는 능력을 잃게 된다. 키들이 모든 파티션에 흩어져서 정렬 순서가 유지되지 않는다. MongoDB에서는 해시 기반 샤딩 모드를 활성화하면 범위 질의가 모든 파티션에 전송돼야 하고, Riak, CouchBase, Voldemort에서는 기본키에 대한 범위 질의가 지원되지 않는다.
Cassandra의 경우 두 가지 파티셔닝 전략 사이에서 타협한다. 테이블을 선언할 때 여러 칼럼을 포함하는 복합 기본키를 지정하고 키의 첫 부분에만 해싱을 적용해 파티션 결정에 사용하면서 남은 칼럼은 SS테이블에서 데이터를 정렬하는 연쇄된 색인으로 사용한다. 따라서 복합 키의 첫 번째 칼럼에 대해서는 값 범위로 검색하는 질의를 쓸 없지만 첫 번째 칼럼에 고정된 값을 지정하면 키의 다른 칼럼에 대해서는 범위 스캔을 효율적으로 실행할 수 잇다.
연쇄된 색인을 사용하면 일대다 관계를 표현하는 우아한 데이터 모델을 만들 수 있다. 예를 들어 특정 사용자가 수정한 문서의 기본키를 (user_id, update_timestamp)로 선택하면 특정한 사용자가 어떤 시간 구간에서 수정한 모든 문서는 한 파티션 내에서 타임스탬프 순으로 정렬된 사태로 저장되며, 따라서 정렬된 상태로 읽어올 수 있다.
쏠린 작업부하와 핫스팟 완화
키를 해싱해서 파티션을 정하면 핫스팟을 줄이는 데 도움이 된다. 하지만 핫스팟을 완벽하게 제거할 수는 없다. 항상 동일한 키를 읽고 쓰는 극단적인 상황에서는 모든 요청이 동일한 파티션으로 쏠리게 된다.
이런 작업부하는 드물곘지만 전혀 없는 것은 아니다. 예를 들어 소셜 미디어 사이트에서 수백만 팔로워를 가진 유명인의 경우, 유명인이 실행한 작업 떄문에 동일한 키에 막대한 양의 데이터를 기록해야 할 수도 있다(키는 유명인의 사용자 ID이거나 댓글을 다는 액션의 ID가 될 것이다). 동일한 ID의 해시값은 동일하므로 해싱은 동일할 것이다.
현대 데이터 시스템은 대부분 크게 쏠린 작업부하를 자동으로 보정하지 못하므로, 애플리케이션에서 쏠림을 완화해야 한다. 간단한 해결책 중 하나는 각 키의 시작이나 끝에 임의의 숫자를 붙이는 것이다. 임의의 10진수 2개만 붙이더라도 한 키에 대한 쓰기 작업이 100개의 다른 키로 균등하게 분산되고, 그 키들은 다른 파티션으로 분산될 수 있다.
다만 다른 키에 쪼개서 쓰면 읽기를 실행할 때 추가적인 작업(100개의 키에 해당하는 데이터 읽어서 조합)해야 하며 추가적으로 저장해야 하는 정보들도 있다. 따라서 이 기법은 요청이 몰리는 소수의 키(유명인)에만 적용하는 것이 타당하다. 쓰기 처리량이 낮은 대다수의 키에도 저용하면 불필요한 오버헤드가 생긴다.
미래에는 데이터 시스템이 쏠린 작업부하를 자동으로 감지해서 보정할 수 있겠지만 아직은 애플리케이션에 대한 트레이드오프를 꼼꼼히 따져볼 필요가 있다.
파티셔닝과 보조 색인
키-값 데이터 모델의 파티셔닝 방식에서는, 보조 색인이 연관되면 상황이 복잡해진다.
보조 색인은 보통 레코드를 유일하게 식별하는 용도가 아니라 특정한 값이 발생한 항목을 검색하는 수단이다. 보조 색인은 관계형 데이터베이스의 핵심 요소이며 문서 데이터베이스에서도 흔하다. 많은 키-값 저장소에서는 구현 복잡도가 추가되는 것을 피하려고 보조 색인을 지원하지 않지만, 보조 색인은 데이터 모델링에 매우 유용하므로 Riak같은 일부 저장소에서는 이를 추가하기 시작했다. 보조 색인은 Solar나 ElasticSearch 같은 검색 서버에게는 존재의 이유다.
보조 색인은 파티션에 깔끔하게 대응되지 않는 문제점이 있다. 보조 색인이 있는 데이터베이스를 파티셔닝하는 데 널리 쓰이는 두 가지 방법이 있다. 문서 기반 파티셔닝과 용어 기반 파티셔닝이다.
문서 기준 보조 색인 파티셔닝
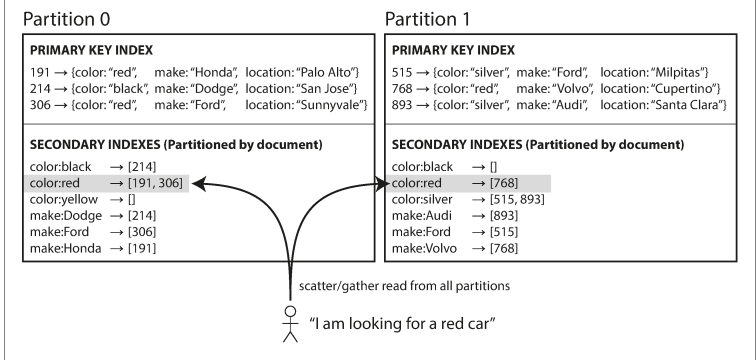
예를 들어 중고차를 판매하는 웹사이트를 운영한다고 하면, 각 항목에는 문서 ID(document ID)라는 고유 ID가 있고 이 문서 ID를 기준으로 파티셔닝한다. 그리고 차를 검색할 때 색상으로 필터링 할 수 있게 color 칼럼/필드에 보조 색인을 만든다. 색인 선언 후 데이터베이스가 데이터가 자동으로 들어오면 해당 데이터가 들어간 파티션에 보조 색인 항목에 해당하는 문서 ID 목록에 추가한다.
이런 색인 방법을 사용하면 각 파티션이 완전히 독립적으로 동작한다. 데이터베이스에 문서 추가/삭제/갱신 등의 쓰기 작업을 실행할 때는 쓰려고 하는 문서 ID를 포함하는 파티션만 다루면 된다. 이러한 까닭에 문서 파티셔닝 색인은 local index(지역 색인)이라고도 한다.
그러나 문서 기준으로 파티셔닝된 색인은 여러 파티션에 데이터가 흩어져 있을 가능성이 있을 수 있다. 따라서 보조 색인 사용시 모든 파티션으로 질의를 보내서 얻은 결과를 모두 모아야 한다. 이러한 방법을 scatter/gather(스캐터/개더)라고 하는데 보조 색인을 써서 읽는 질의는 큰 비용이 들 수 있다. 여러 파티션에서 질의를 병렬 실행하더라도 스캐터/개더는 꼬리 지연 시간 증폭이 발생하기 쉽다. 그럼에도 보조 색인을 문서 기준으로 파티셔닝하는 경우가 많다. MongoDB, Riak, Cassandra, ElasticSearch,SolarCloud, VoltDB 모두 문서 기준으로 파티셔닝된 보조 색인을 사용한다. 데이터베이스 벤더들은 대부분 보조 색인 질의가 단일 파티션에서만 실행되도록 파티셔닝 방식을 설계하기를 권장하지만 여러 보조 색인을 통한 질의와 같은 경우로 항상 가능하지 않다.
용어 기준 보조 색인 파티셔닝
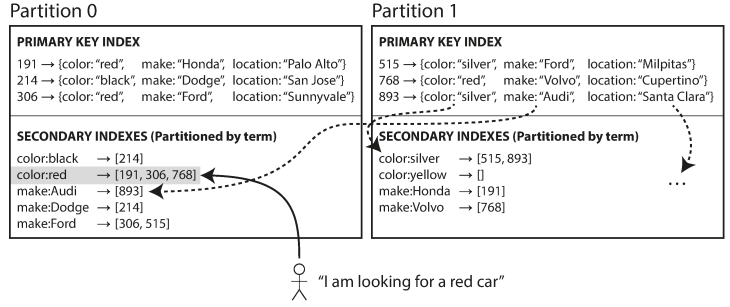
각 파티션이 자신만의 보조 색인을 갖게 하는 대신, 모든 파티션의 데이터를 담당하는 global index(전역 색인)을 만들 수도 있다. 하지만 한 노드에만 색인을 저장하면 병목이 되어 파티셔닝의 목적을 해치기 때문에, 전역 색인도 용어에 따라 파티셔닝해야 한다.
위의 예시에서 볼 수 있듯이 color 색인에서 a~r까지의 글자로 시작하는 색깔은 파티션 0에, s부터 z까지의 글자로 시작하는 색깔은 파티션 1에 저장되도록 파티셔닝되었다. 이는 제조사도 마찬가지로 되어 있다. 이렇게 찾고자 하는 용어에 따라 색인의 파티션이 결정되므로 이런 식의 색인을 term-partitioned(용어 기준으로 파티셔닝됐다)라고 한다. 여기서 용어란 문서에 등장하는 모든 단어를 말한다.
이전처럼 색인을 파티셔닝할 때도 용어 자체를 사용하거나, 용어의 해시값을 사용할 수 있다. 전자의 경우 범위 스캔에 유용한 반면 후자는 부하가 좀 더 고르게 분산된다.
문서 파티셔닝 색인에 비해 전역 색인이 갖는 이점은 원하는 스캐터/개더 없이 용어를 포함하는 파티션으로만 요청을 보내면 되기 때문에 읽기가 효율적이라는 것이다. 다만 전역 색인은 단일 문서가 쓰일 때 해당 문서의 색인(용어)들이 여라 파티션에 속해있을 수 있기 때문에 쓰기가 느리고 복잡해진다는 단점이 있다. 이 경우 쓰기에 영향받는 모든 파티션에 걸친 분산 트랜잭션을 실행해야 하는데, 모든 데이터베이스에서 분산 트랜잭션을 지원하지 않는다.
색인은 이상적으로 항상 최신 상태여야 하며 모든 문서에 색인이 반영되야 하지만, 현실에서는 색인은 대개 비동기로 갱신된다. 예를 들어 Amazon DynamoDB는 정상적인 상황에서는 전역 보조 색인을 갱신하는 데 1초도 안 걸리지만 인프라에 결함이 생기면 반영 지연 시간이 더 길어질 수도 있다.
전역 용어 파티셔닝 색인의 다른 사용처로는 Riak의 검색 기능과 Oracle Data Warehouse가 있다. Oracle Data Warehouse의 경우 지역 색인과 전역 색인 사이에서 선택할 수 있다.
파티션 재균형화
시간이 지나면 데이터베이스에 변화가 생긴다.
- 질의 처리량이 증가해서 늘어난 부하를 처리하기 위해 CPU를 더 추가하고 싶다.
- 데이터셋 크기가 증가해서 데이터셋 저장에 사용할 디스크와 램을 추가하고 싶다.
- 장비에 장애가 발생해서 그 장비가 담당하던 역할을 다른 장비가 넘겨받아야 한다.
이런 변화가 생기면, 데이터와 요청이 한 노드에서 다른 노드로 옮겨져야 한다. 클러스터에서 한 노드가 담당하던 부하를 다른 노드로 옮기는 과정을 rebalancing(재균형화)라고 한다.
어떤 파티셔닝 방식을 쓰는지에 무관하게 재균형화가 실행될 때 보통 만족시킬 것으로 기대되는 최소 요구사항이 있다.
- 재균형화 후, 부하(데이터 저장소, 읽기 쓰기 요청)가 클러스터 내에 있는 노드들 사이에 균등하게 분배돼야 한다.
- 재균형화 도중에도 데이터베이스는 읽기 쓰기 요청을 받아들여야 한다.
- 재균형화가 빨리 실행되고 네트워크와 디스크 I/O 부하를 최소화 할 수 있도록 노드들 사이에 데이터가 필요 이상으로 옮겨져서는 안 된다.
재균형화 전략
파티션을 노드에 할당하는 방법이 몇 가지 있다. 하나씩 간락히 살펴보자.
쓰면 안되는 방법: 해시값에 Mod N 연산을 실행
앞에서 키의 해시값 기준으로 파티션이 할 때는 사용 가능한 해시값 범위를 나누고 각 범위를 한 파티션에 할당하는 게 최선이라고 했다. 하지만 mod N 연산을 실행하면 0부터 N-1까지 쉽게 각 키를 노드에 할당할 수 있는데 왜 이 방식을 쓰지 않을까?
그 이유는 노드 개수 N이 바뀌면 대부분의 키가 노드 사이에 옮겨져야 하기 때문이다. 예를 들어 hash(key) = 123456이라고 하자. 처음에 노드가 10개라면 이 키는 노드 6에 할당되지만, 노드가 11대로 늘어나면 키가 노드 3으로, 노드가 12대로 늘어나면 노드 0으로 옮겨져야 한다. 이렇게 키가 자주 이동하면 재균형화 비용이 지나치게 커진다.
데이터를 필요 이상으로 이동하지 않는 방법이 필요하다.
파티션 개수 고정
다행스럽게도 상당히 간단한 해결책이 있다. 그것은 바로 파티션을 노드 대수보다 많이 만들고, 각 노드에 여러 파티션을 할당하는 것이다. 예를 들어 노드 10대로 구성된 클러스터에서 실행되는 데이터베이스는 처음부터 파티션을 1,000개로 쪼개서 각 노드마다 약 100개의 파티션을 할당하는 것이다.
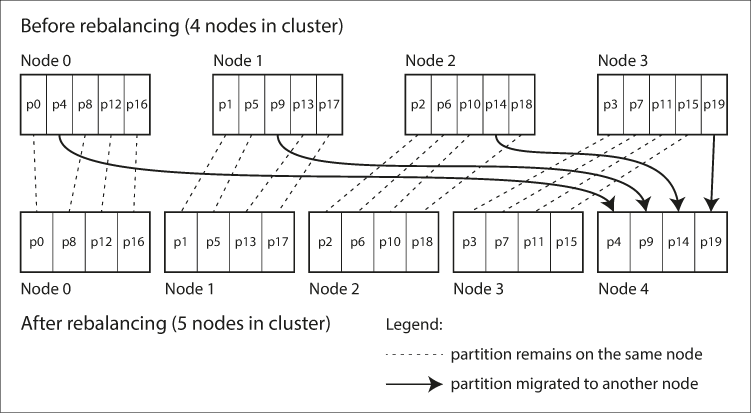
클러스터에 노드가 추가되면 새 노드는 기존 노드들에게서 파티션 몇 개를 뺏어올 수 있다. 클러스터에서 노드가 제거되면 이 과정이 반대로 실행된다. 파티션은 노드 사이에서 통째로 이동하기만 하면 되고, 파티션에 할당된 키도 변경되지 않는다. 유일한 변화는 노드에 어떤 파티션이 할당되는가 뿐이다.
파티션 할당 변경은 즉시 반영되지 않고 네트워크를 통해 대량의 데이터를 전송해야 하므로 시간이 좀 걸린다. 따라서 데이터 전송이 진행 중인 동안에 읽기/쓰기가 실행되면 기존에 할당된 파티션을 활용한다. 이 외에도클러스터에 성능이 좀 더 좋은 하드웨어가 섞여 있을 수도 있으므로, 성능이 좋은 노드에 파티션을 더 할당함으로써 더 많은 부하를 담당하게 할 수도 있다.
이런 재균형화 방법은 Riak, ElasticSerach, CouchBase, Voldemort에서 사용된다. 이 방식을 사용할 때는 보통 데이터베이스가 처음 구축될 때 파티션 개수가 고정되고 이후에 변화지 않는다. 이론적으로는 파티션을 쪼개거나 합치는게 가능하지만 파티션 개수가 고정되면 운영이 단순해지므로 고정 파티션을 사용하는 데이터베이스는 파티션 분할을 지원하지 않는다.
따라서 처음 설정된 파티션 개수가 사용 가능한 노드 대수의 최대치가 되므로, 파티션 개수는 미래의 데이터 증가치를 수용할 수 있을 정도로 충분히 높은 값으로 선택해야 한다. 그러나 개별 파티션도 관리 오버헤드가 있으므로 너무 큰 수를 선택하면 역화과를 낳을 수 있다.
적절한 파티션의 개수를 정하는 것도 어렵지만, 각 파티션의 크기도 적절해야 한다. 각 파티션은 전체 데이터의 고정된 비율이 포함되므로 개별 파티션의 크기는 클러스터의 전체 데이터 크기에 비례해서 증가한다. 파티션이 너무 크면 재균형화를 실행할 때와 노드 장애로부터 복구할 때 비용이 너무 크고, 너무 작으면 오버헤드가 커진다.
동적 파티셔닝
키 범위 파티셔닝을 사용하는 데이터베이스에서는 파티션 경계를 잘못 지정하면 모든 데이터가 한 파티션에 저장되고 나머지 파티션은 텅 빌 수도 있다.
이런 이유로 HBase나 ResyncDB처럼 키 범위 파티셔닝을 사용하는 데이터베이스에서는 파티션을 동적으로 만든다. 파티션 크기가 설정된 값을 넘어서면 파티션을 두 개로 쪼개 각각에 원래 파티션의 절반 정도의 데이터가 포함되게 하고, 반대로 파티션 크기가 임곗값 아래로 떨어지면 인접한 파티션과 합쳐질 수 있다. 이 과정은 B 트리의 최상위 레벨에서 실행되는 작업과 유사하다. 파티션이 다른 노드로 이동할 때는 HBase의 경우 기반 분산 파일 시스템인 HDFS를 통해 파티션 파일이 전송된다.
동적 파티셔닝은 파티션 개수가 전체 데이터 용량에 맞춰 조정된다는 이점이 있지만, 초기 데이터베이스에서는 파티션 경계를 정하기 위한 사전 정보가 없어 파티션이 하나인 함정이 있다. 이 대문에 모든 쓰기 요청이 하나의 노드에서만 실행될 수 있다. 이 문제를 완화하기 위해 HBase와 MongoDB에서는 빈 데이터베이스에 초기 파티션 집합을 설정할 수 있게 한다(pre-splitting(사전 분할)이라고 부른다). 이를 위해 키가 어떤 식으로 분할될지 미리 알아야 한다.
동적 파티셔닝은 키 범위 파티셔닝과 해시 파티셔닝 모두에서 사용될 수 있다. MongoDB 2.4 버전부터 키/해시 파티셔닝 모두에 대해 동적 파티셔닝을 지원한다.
노드 비례 파티셔닝
동적 파티셔닝의 경우 파티션의 개수가 노드 대수와 독립적이다. 이와 반대로 Cassandra와 Ketama에서 사용되는 방법은 파티션 개수가 노드 대수에 비례하는, 즉 노드당 할당되는 파티션 개수가 고정되는 노드 비례 파티셔닝이다. 노드 대수가 변함 없는 동안은 개별 파티션 크기가 데이터셋 크기에 비례해 증가하지만 노드 대수를 늘리면 파티션 크기는 다시 작아진다. 일반적으로 데이터 용량이 클수록 데이터를 저장할 노드도 많이 필요하므로 이 방법을 쓰면 개별 파티션 크기도 상당히 안정적으로 유지된다.
새 노드가 클러스터에 추가되면 고정된 개수의 파티션을 무작위로 선택해 분할하고, 분할한 파티션의 절반을 새 노드에 할당하낟. 파티션을 무작위로 선택해서 균등하지 않은 분할이 생길 수 있지만 여러 파티션에 대해 평균적으로 보면 새 노드는 기존 노드들이 담당하던 부하에서 균등한 몫을 할당받게 된다. 또한 Cassandra 3.0에서는 불균등한 분할을 회피할 수 있는 대안적인 재균형화 알고리즘이 추가됐다.
파티션 경계를 무작위로 선택하려면 해시 기반 파티셔닝을 사용해야 한다(해시 함수를 통해 생성된 숫자 범위로부터 파티션 경계를 선택할 수 있도록). 실제로 이 방법은 일관성 해싱의 원래 정의에 가장 가깝게 대응한다. 최근에 나온 해시 함수를 쓰면 메타데이터 오버헤드를 낮추면서도 비슷한 효과를 얻을 수 있다.
운영: 자동 재균형화와 수동 재균형화
그렇다면 재균형화는 자동으로 실행해야 할까? 아니면 수동으로 실행해야 할까?
완전 자동 재균형화와 완전 수동 재균형화 사이에는 중간 지점이 있다. 이를테면 CouchBase, Riak, Voldemort는 자동으로 파티션 할당을 제안하지만 관리자가 확정해야 한다.
완전 자동 재균형화는 일상적인 유지보수에 손이 덜 가므로 편리할 수 있지만, 자동으로 요청 경로를 재설정하고 대량의 데이터를 노드 사이에 이동하는 작업을 수행하므로 주의깊게 처리하지 않으면 네트워크나 노드에 과부하가 걸릴 수도 있고, 뜻하지 않게 다른 요청의 성능이 저하될 수 있다. 또한 자동화가 자동 장애 감지와 조합되면 일시적으로 느려진 노드를 장애로 파악하는 순간 자동 재균형화가 일어나 시스템에 부하를 더하기 때문에 장애 상황을 악화시키고 연쇄 장애를 일으킬 수 있다.
이런 이유로 재균형화 과정에는 사람이 개입하는 게 좋을 수도 있다. 완전 자동 처리보다는 느릴 수 있지만 운영상 예상치 못한 일을 방지하는 데 도움될 수도 있다.
요청 라우팅
이제 데이터셋을 여러 장비에서 실행되는 여러 노드에 파티셔닝할 수 있다. 하지만 아직 해결되지 않은 문제가 있다. 클라이언트에서 요청을 보내려고 할 떄 어느 노드로 접속해야 하는지 어떻게 알 수 있을까? 파티션이 재균형화되면 노드에 할당되는 파티션이 바뀐다. 때문에 이러한 파티션 할당 변경을 훤히 알고 있어야 한다.
이 문제는 데이터베이스에 국한되지 않은 더욱 일반적인 문제인 service discovery(서비스 찾기)의 일종이다. 네트워크를 통해 접속되는 소프트웨어라면 어떤 것이든지, 특히 고가용성을 지향하는 소프트웨어라면 모두 이 문제가 있다. 여러 회사에서 자체 서비스 찾기 도구를 개발했고 그중 다수가 오픈소스로 공개됐다.
상위 수준에서 보면 이 문제는 몇 가지 다른 접근법이 있다.
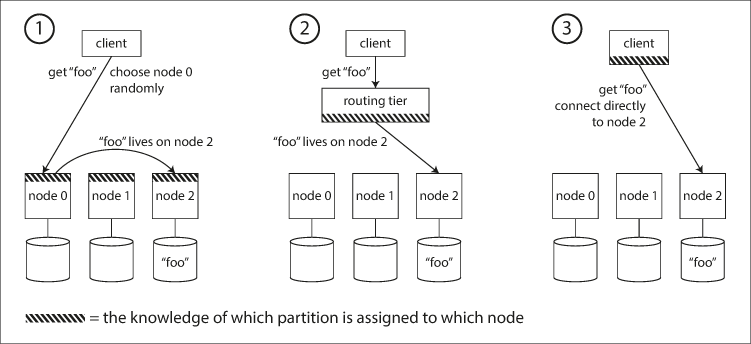
- 클라이언트가 아무 노드에나 접속하게 한다(예를 들어 라운드 로빈 로드 밸런서를 통해). 만약 해당 노드에 마침 요청을 적용할 파티션이 있다면 거기서 요청을 직접 처리할 수 있다. 그렇지 않으면 요청을 올바른 노드로 전달해서 응답을 받고 클라이언트에게 응답을 전달한다.
- 클라이언트의 모든 요청을 라우팅 계층으로 먼저 보낸다. 라우팅 계층에는 각 요청을 처리할 노드를 알아내고 그에 따라 해당 노드로 요청을 전달한다. 라우팅 계층 자체에서는 아무 요청도 처리하지 않는다. 파티션 인지(partition-aware) 로드 밸런서로 동작할 뿐이다.
- 클라이언트가 파티셔닝 방법과 파티션이 어떤 노드에 할당됐는지를 알고 있게 한다. 이 경우 클라이언트는 중개자 없이 올바른 노드로 직접 접속할 수 있다.
모든 경우에 핵심 문제는 라우팅 결정을 내리는 구성요소(노드 중 하나, 혹은 라우팅 계층, 혹은 클라이언트)가 노드에 할당된 파티션의 변경 사항을 어떻게 아느냐다.
이 문제는 참여하는 모든 곳에서 정보가 일치해야 하므로 다루기 어렵다. 그렇지 않으면 요청이 잘못된 노드로 전송되고 제대로 처리되지 못한다. 분산 시스템에서 합의를 이루는 데 쓰이는 프로토콜이 있지만 제대로 구현하기가 까다롭다.
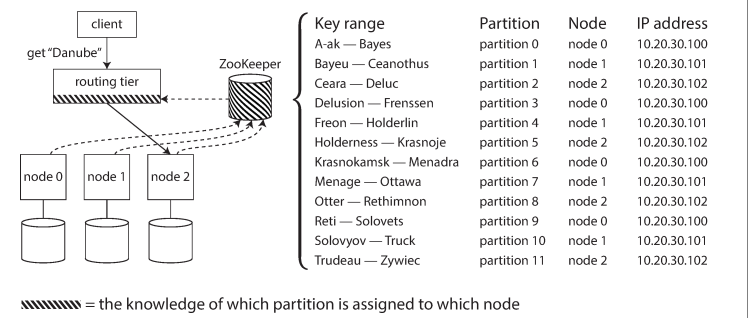
위의 그림처럼 많은 분산 데이터 시스템은 클러스터 메타데이터를 추적하기 위해 Zookeeper(주키퍼)와 같은 별도의 코디네이션 서비스를 사용한다. 각 노드는 주키퍼에 자신을 등록하고, 주키퍼는 파티션과 노드 사이의 신뢰성 있는 할당 정보를 관리한다. 라우팅 계층이나 파티션 인지 클라이언트 같은 다른 구성 요소들은 주키퍼에 있는 정보를 구독한다. 이후 파티션 변경이 있으면 주키퍼는 라우팅 계층에 이를 알려서 라우팅 정보를 최신으로 유지할 수 있게 한다.
LinkedIn의 Espresso는 Helix(Zookeeper에 의존함)를 써서 클러스터를 관리하며 HBase, SolarCloud, Kafka도 파티션 할당을 추적하는 데 주키퍼를 사용한다. MongoDB도 아키텍처는 비슷하지만 자체적인 config server(설정 서버) 구현에 의존하고 mongos(몽고스) 데몬을 라투이 계층으로 사용한다.
Cassandra와 Riak은 이와 다르게 gossip protocol(가십 프로토콜)을 사용해서 클러스터 상태 변화를 노드 사이에 퍼뜨린다. 이를 통해 아무 노드가 요청을 받을 수 있고, 요청을 받은 노드는 요청을 처리할 파티션을 갖고 있는 올바른 노드로 요청을 전달해준다(위의 1번쨰 방법처럼). 이 모델은 데이터베이스 노드에 복잡성을 더하지만 Zookeeper같은 외부 코디네이션 서비스에 의존하지 않는다.
CouchBase는 재균형화를 자동으로 실행하지 않아서 설계가 단순하다. 따라서 보통 클러스터 노드로부터 변경된 라우팅 정보를 알아내는 moxi(목시)라는 라우팅 계층을 설정한다.
클라이언트는 라우팅 계층을 사용하거나 임의의 노드로 요청을 보낼 때도 접속할 IP 주소를 알아내야 하는데, IP 주소는 노드에 할당된 파티션 정보만큼 자주 바뀌지 않으므로 IP 주소를 찾는 데는 대개 DNS를 쓰는 것으로 충분하다.
병렬 질의 실행
지금까지는 단일 키를 읽거나 쓰는 매우 간단한 질의에 대해서만 설명했다. 이는 대부분의 NoSQL 분산 데이터스토어에서 지원하는 접근 수준이다.
그러나 분석용으로 자주 사용되는 massively parallel processing, MPP(대규모 병렬 처리) 관계형 데이터베이스 제품은 훨씬 더 복잡한 종류의 질의를 지원한다. 보통 join(조인), filtering(필터링), grouping(그룹화), aggregation(집계) 연산을 포함하는데, 이 때 MPP 질의 최적화기는 이런 복잡한 질의를 여러 실행 단계와 파티션을 분해하며 이들 중 다수는 데이터베이스 클러스터 내의 서로 다른 노드에서 병렬적으로 실행될 수 있다. 데이터셋의 많은 부분을 스캔하는 연산은 특히 병렬 실행의 혜택을 받는다.
데이터 웨어하우스 질의 고속 병렬 실행은 전문적인 주제이며 분석 업무가 비즈니스적으로 중요해짐에 따라 상업적 관심을 많이 받고 있다. 병렬 질의 실행 기법 몇 가지는 10장에서 살펴본다.
정리
이번 장에서는 대용량 데이터셋을 더욱 작은 데이터셋으로 파티셔닝하는 다양한 방법을 살펴봤다. 저장하고 처리할 데이터가 너무 많아서 장비 한 대로 처리하는 게 불가능해지면 파티셔닝이 필요하다.
파티셔닝의 목적은 핫스팟(불균형적으로 높은 부하를 받는 노드)이 생기지 않게 하면서 데이터와 질의 부하를 여러 장비에 균일하게 분배하는 것이다. 이 목적을 달성하기 위해서는 데이터에 적합한 파티셔닝 방식을 선택해야하고, 클러스터에 노드가 추가/제거될 때 파티션 재균형화를 실행해야 한다.
두 가지 주요 파티셔닝 기법을 설명했다.
- 키 범위 파티셔닝: 키가 정렬돼 있고 개별 파티션은 어떤 최솟값과 최댓값 사이에 속하는 모든 키를 담당한다. 키가 정렬돼 있어 범위 질의가 효율적이라는 장점이 있지만, 애플리케이션에서 정렬 순서가 서로 가까운 키에 자주 접근하면 핫스팟이 생길 위험이 있다. 이 방법에서는 보통 한 파티션이 너무 커지면 키 범위를 두 개로 쪼개 동적으로 재균형화를 실행한다.
- 해시 파티셔닝: 각 키에 해시 함수를 적용하고 개별 파티션은 특정 범위의 해시값을 담당한다. 이 방법을 쓰면 키 순서가 보장되지 않아 범위 질의가 비효율적이지만 부하를 더육 균일하게 분산할 수 있다. 해시 파티셔닝을 사용할 때는 보통 고정된 개수의 파티션을 미리 만들어 각 노드에 몇 개씩의 파티션을 할당하며 노드가 추가되거나 제거되면 파티션을 통째로 노드 사이에서 이동한다. 동적 파티셔닝을 쓸 수도 있다.
두 가지 방법을 섞어 쓸 수도 있다. 이를테면 키의 일부분은 파티션 식별용으로, 나머지 부분은 정렬 순서용으로 만든 복합 키를 사용하는 것이다.
파티셔닝과 보조 색인 사이의 상호작용에 대해서도 얘기했다. 보조 색인도 파티셔닝이 필요한데 두 가지 방법이 있다.
- 문서 파티셔닝 색인(지역 색인): 보조 색인을 기본키와 값이 저장된 파티션에 저장한다. 쓸 때는 파티션하나만 갱신하면 되지만 보조 색인을 읽으려면 모든 파티션에 걸쳐서 스캐터/개더를 실행해야 한다.
- 용어 파티셔닝 색인(전역 색인): 색인된 값을 사용해서 보조 색인을 별도로 파티셔닝한다. 보조 색인 항목은 기본키의 모든 파티션에 있는 레코드를 포함할 수도 있다. 문서를 쓸 때는 보조 색인 여러 개를 생신해야 하지만 읽기는 단일 파티션에서 실행될 수 있다.
끝으로 단순한 파티션 인지 로드 밸런서에서 복잡한 병렬 질의 처리 엔진까지 질의를 올바른 파티션으로 라우팅하는 기법도 다뤘다.
설계상 모든 파티션은 대부분 독립적으로 동작한다. 그렇기 때문에 파티셔닝된 데이터베이스는 여러 장비로 확장될 수 있다. 이 때 여러 파티션에 기록해야 하는 연산은 검증하기 어려울 수 있다. 예를 들어 한 파티션에는 쓰기 성공했지만 다른 파티션에서 실패하면 어떻게 될까? 이어지는 장애서 이 의문을 다룬다.
Reference: http://www.yes24.com/Product/Goods/59566585
데이터 중심 애플리케이션 설계 - YES24
데이터는 오늘날 시스템을 설계할 때 마주치는 많은 도전 과제 중에서도 가장 중심에 있다. 확장성, 일관성, 신뢰성, 효율성, 유지보수성과 같은 해결하기 어려운 문제를 파악해야 할 뿐 아니라
www.yes24.com
'백엔드 > 분산 시스템' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] 08장. 분산 시스템의 골칫거리 (0) | 2023.02.12 |
|---|---|
| [데이터 중심 애플리케이션 설계] 07장. 트랜잭션 (0) | 2023.02.05 |
| [데이터 중심 애플리케이션 설계] Part 1. 데이터 시스템의 기초 (0) | 2023.01.22 |
| [데이터 중심 애플리케이션 설계] 04장. 부호화와 발전 (0) | 2023.01.15 |
| [데이터 중심 애플리케이션 설계] 03장. 저장소와 검색 (0) | 2023.01.09 |