Part 1. 데이터 시스템의 기초
데이터 모델은 해결하려는 문제를 어떻게 생각해야 하는지에 대해서 지대한 영향을 미친다.
데이터 모델은 그 위에서 소프트웨어가 할 수 있는 일과 할 수 없는 일에 지대한 영향을 준다.
대부분의 애플리케이션은 데이터 모델의 계층을 둬서 만들어지며, 데이터 모델의 각 계층의 핵심적인 문제는 다음 하위 계층 관점에서 데이터 모델을 표현/추상화하는 방법이다.
이 장에서는 다양한 범용 데이터 모델과 다양한 질의 언어를 살펴본다.
- relational model(관계형 모델)
- document model(문서 모델)
- graph-basd data model(그래프 기반 데이터 모델)
관계형 모델과 문서 모델
오늘날 가장 잘 알려진 데이터 모델은 관계형 모델이다.
관계형 모델을 기반으로 한 SQL은 relation(관계)로 구성되고 각 관계는 순서가 없는 tuple(튜플)의 모음이다.
관계형 데이터는 본래 비즈니스 데이터 처리(트랜잭션 처리/일괄 처리)를 위해 사용되었다. 현재는 더욱 폭넓은 영역(웹에서 볼 수 있는 대부분의 서비스: 게시물, SNS, SaaS, 게임)에서 여전히 사용하고 있다.
NoSQL의 탄생
NoSQL은 관계형 모델의 우의를 뒤집으려고 하는 가장 최신 시도이며, 대규모 데이터셋/높은 쓰기 처리량 달성/확장성/오픈소스/특수 질의 등의 관점에서 채택되고 있다.
애플리케이션은 저마다 요구사항이 다르기 떄문에, 관계형 데이터베이스가 비관계형 데이터스토어와 함께 사용하는 polyglot persistence(다중 저장소 지속성) 형태로 사용될 것이다.
객체 관계형 불일치
오늘날 대부분의 애플리케이션은 객체지향 프로그래밍 언어로 개발되는데, 이는 SQL 데이터 모델과의 모델 불일치로 거추장스러운 전환 계층을 수행해야 한다. 이를 impedance mismatch(임피던스 불일치)라고 부른다.
ORM(객체 관계형 매핑) 프레임워크가 전환 계층에 필요한 boilerplate code(사용구 코드)의 양을 줄이지만 두 모델 간의 차이를 완벽히 숨길 수 없다.
예를 들어 이력서를 표현할 때 관계들을 다양한 방법으로 나타낼 수 있다.
- 전통적인 SQL 모델에서는 정규화를 통해 모든 정보를 개별 테이블에 넣고, 외래 키로 테이블을 참조한다.
- SQL 표준의 최신 버전은 XML 데이터 및 구조화된 datatype(데이터타입)을 지원하므로 단일 row에 다중 값을 저장할 수 있다.
- 이력서의 모든 정보를 JSON이나 XML 문서로 부호화해 데이터베이스의 텍스트 칼럼에 저장한 다음에 애플리케이션이 구조와 내용을 해석하게 하게 한다.
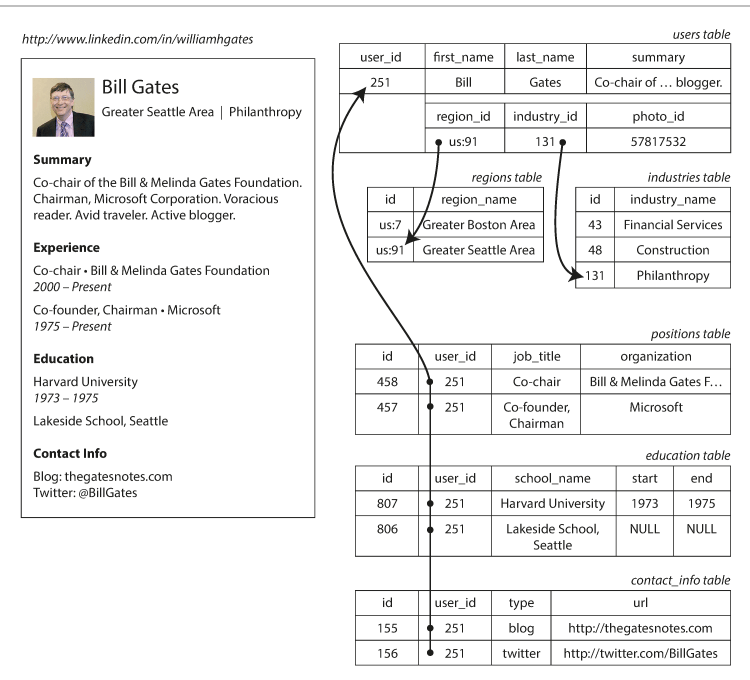
// JSON 문서로 표현한 링크드인 프로필
{
"user_id":251,
"first_name":"Bill",
"last_name":"Gates",
"summary":"Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id":"us:91",
"industry_id":131,
"photo_url":"/p/7/000/253/05b/308dd6e.jpg",
"positions":[
{
"job_title":"Co-chair",
"organization":"Bill & Melinda Gates Foundation"
},
{
"job_title":"Co-founder, Chairman",
"organization":"Microsoft"
}
],
"education":[
{
"school_name":"Harvard University",
"start":1973,
"end":1975
},
{
"school_name":"Lakeside School, Seattle",
"start":null,
"end":null
}
],
"contact_info":{
"blog":"<http://thegatesnotes.com>",
"twitter":"<http://twitter.com/BillGates>"
}
}
이력서와 같은 데이터 구조는 모든 내용을 갖추고 있는 문서라서 JSON 표현에 매우 적합하며, 관계형 모델의 multi-table(다중 테이블) 스키마보다 더 나은 locality(지역성)를 가지고 있다.
이는 관계형 모델의 경우 프로필을 가져오려면 연관된 모든 테이블에 대한 다중 질의/다중 조인을 수행해야 하지만, JSON 표현의 경우 모든 관련 정보가 한 곳에 있어 질의 하나로 충분하기 때문이다.
일대다 관계는 의미상 데이터 트리 구조와 같다. 이 트리 구조는 JSON 표현에서 명시적으로 드러난다

다대일과 다대다 관계
ID로 저장함으로써 중복을 제거할 수 있고, 이것이 데이터베이스 정규화의 핵심 개념이다.
중복된 데이터를 정규화하려면 many-to-one(다대일) 관계가 필요한데, 이는 문서 모델에 적합하지 않다. 따라서 애플리케이션 레벨에서 다중 질의를 통해 조인을 흉내 내야 한다.
또한 애플리케이션에 기능이 추가되면서 데이터가 상호 연결되는 경향이 있기 때문에, 조인이 필요해질 수 있다. (학교, 조직 등은 엔티티로서 참조하며, 이를 통해 학교/조직의 추가 정보를 쉽게 확인할 수 있다)
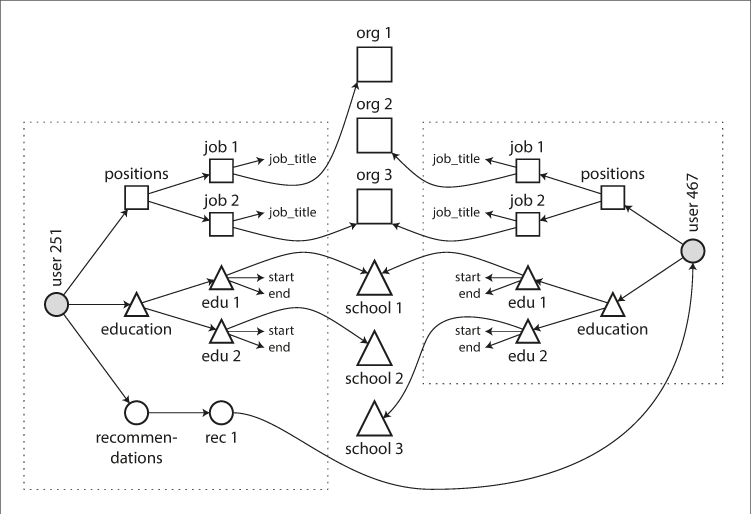
문서 데이터베이스는 역사를 반복하고 있나?
데이터베이스에서 다대다 관계를 표현하는 가장 좋은 방법에 대한 논쟁이 최근에 다시 열렸고, 이 논쟁은 초기 데이터베이스 시스템에서부터 시작된 논쟁이기도 하다.
초기 데이터베이스인 IBM의 IMS(Information Management System)는 계층 모델을 사용하였으며, 다대다 관계에서는 개발자가 데이터를 중복해서 넣을지 레코드 간의 관계를 수동으로 해결할지를 직접 결정해야 했다.
이를 해결하기 위해 관계형 모델과 네트워크 모델이 제안되었다.
네트워크 모델
네트워크 모델은 CODASYL(코다실)이라는 위원회에서 표준화하였다. 코다실 모델은 계층 모델을 일반화하였는데, 네트워크 모델에서는 레코드가 다중 부모가 있을 수 있고, 레코드 간의 연결이 프로그래밍의 포인터와 비슷하다. 레코드에 접근하기 위해서는 최상위 레코드에서 연결 경로를 따라가는 방버이며 이를 접근 경로라고 한다.
네트워크 모델은 만약 레코드가 다중 부모를 가지고 있다면 애플리케이션 코드가 다양한 관계를 모두 추적해야 하기 때문에, 데이터베이스 질의 코드가 복잡해지는 문제가 발생한다. 접근 경로를 변경할 수는 있지만 관련된 질의 코드들을 모두 재작성해야 한다.
관계형 모델
대조적으로 관계형 모델은 모든 데이터를 배치하기 때문에, relation은 단순히 tuple의 컬렉션이며, 따라서 데이터를 보고 싶을 때 따라가야 하는 접근 경로가 없다. 일부 또는 모든 tuple을 선택해서 읽고 삽입할 수 있다.
관계형 데이터베이스에서 query optimizer(질의 최적화기)는 데이터의 색인을 선언하면 자동으로 가장 적합한 색인을 사용하여 질의를 어떤 순서로 수행할지 결정한다. 이 선택은 접근 경로이지만, 자동으로 만든다는 것에서 차이가 있다.
관계형 데이터베이스를 위한 query optimizer는 복잡하지만 한 번 만들면 데이터베이스를 사용하는 모든 애플리케이션이 혜택을 받을 수 있다.
문서 데이터베이스와의 비교
문서 데이터베이스는 상위 레코드에 중첩된 레코드를 저장하는 계층 모델의 측면을 띄고 있다.
하지만 다대일과 다대다 관계를 표현할 때 관계형 데이터베이스와 문서 데이터베이스는 모두 관련 항목은 고유한 식별자(관계형: foreign key/왜래 키, 문서: document reference/문서 참조)로 참조한다.
관계형 데이터베이스와 오늘날의 문서 데이터베이스
데이터 모델의 차이점에 따른 비교
- 문서 데이터 모델: 스키마 유연성, 지역성을 기반한 더 나은 성능, 애플리케이션에서 사용하는 데이터 구조와 더 가까움
- 관계형 모델: 조인, 다대일, 다대다 관계를 더 잘 지원함
어떤 데이터 모델이 애플리케이션 코드를 더 간단하게 할까?
애플리케이션에서 데이터가 문서와 비슷한 구조라면 문서 모델을 사용하는 것이 좋다. 관계형 기법의 경우 데이터를 여러 테이블로 shredding(찢기) 때문에, 애플리케이션이 복잡해진다.
다만 문서 모델은 문서 내 중첩 항목을 바로 참조할 수 없다는 제한이 있고, 조인을 미흡하게 지원한다.
만약 애플리케이션에서 다대다 관계를 사용한다면 애플리케이션에서 조인 등의 추가 작업을 수행해야 하기 때문에 문서 모델의 매력이 떨어진다.
결국 데이터 간의 관계 유형에 따라 데이터 모델을 선택해야 한다.
문서 모델에서의 스키마 유연성
문서 데이터베이스의 schemaless(스키마리스)가 아닌, schema-on-read(읽기 스키마, 데이터를 읽을 때 해석되는 암묵적인 데이터 구조)이다. 이 반대되게 관계형 데이터베이스는 schema-on-write(쓰기 스키마, 쓰여진 모든 데이터는 스키마를 따르고 있음이 보장됨)이다.
write-on-schema는 데이터 구조가 변경되어야 할 때, ALTER TABLE 등으로 스키마 migration(마이크레이션)을 수행한다.
read-on-schema는 컬렉션 안의 데이터가 여러 다른 유형으로 구성되어 있을 떄 유리하다. 이는 각 데이터 유형 별로 테이블로 넣는 방법이 실용적이지 않고, 언제나 변경될 수 있기 떄문이다.
질의를 위한 데이터 지역성
웹 페이지 상에 문서를 보여주는 동작처럼, 애플리케이션이 자주 전체 문서에 접근해야 할 때는 storage locality(저장소 지역성)을 활용하면 성능 이점이 있다.
데이터베이스는 문의 작은 부분만 접근해서 전체 문서를 적재해야하기 때문에 큰 문서에서는 낭비일 수 있다. 이를 위해 문서를 작게 유지해야 하는데, 이 때문에 문서 데이터베이스의 유용성이 떨어지는 현상이 발생한다.
지역성을 위해서 데이터를 함께 그룹화하는 개념은 문서 모델에만 국한되지 않는다. 오라클의 multi-table index cluster table(다중 테이블 색인 클러스터 테이블), Bigtable/Cassandra/HBase의 column-family(칼럼 패밀리) 기능이 지역성 특성을 제공한다.
문서 데이터베이스와 관계형 데이터베이스의 통합
관계형 데이터베이스와 문서 데이터베이스는 시간이 지남에 따라 점점 더 비슷해지고 있다. (관계형 데이터베이스의 XML/JSON 지원, 문서 데이터베이스의 관계형 조인 연산 지원)
각 데이터 모델이 서로 부족한 부분을 보완하고 있는 것이다. 이에 따라 애플리케이션은 필요에 따라 가장 적합한 기능을 조합해 사용하면 되는 것이다.
관계형과 문서의 혼합 모델은 미래 데이터베이스들이 가야 할 올바른 길이다.
데이터를 위한 질의 언어
관계형 모델이 등장함에 따라 데이터를 질의하는 새로운 방법도 함께 나타났다. SQL이나 관계 대수는 선언형 질의 언어인 반면 IMS은 명령형 코드를 사용해 데이터베이스에 질의한다. 또한 일반적인 프로그래밍 언어가 명령형 언어이다.
- Imperative(명령형) 질의 언어는 특정 연산을 수행하게끔 컴퓨터에게 지시한다.
function getSharks() {
var sharks = [];
for (var i=0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
}
예를 들어 프로그래밍 언어에서는 코드를 한 줄씩 단계별로 실행하여, 변수를 갱신하고 루프를 돌고 등의 작업을 수행한다.
- Declarative(선언형) 질의 언어는 목표를 달성하기 위한 방법이 아닌, 알고자 하는 결과에 대한 조건과 데이터의 변환을 지정하기만 하면 된다.
SELECT * FROM animals WHERE family = 'Sharks';
질의의 수행 방법은 데이터베이스 시스템의 질의 최적화기가 할 일이다.
선언형 질의 언어의 중요한 점은 데이터베이스 엔진의 상세 구현이 숨겨져 있어 질의를 변경하지 않고도 데이터베이스 시스템의 작동 방식을 변경할 수 있다는 점이다. 명령형 질의에는 데이터의 순서가 명시되는데, 이는 데이테베이스의 변경에 취약하다. 이와 달리 선언형 질의는 데이터의 순서가 명시되어 있지 않기 때문에 데이터베이스를 변경하고 최적화 할 수 있다.
또한 선언형 언어는 병렬 실해에 적합하다. 명령형 코드는 명령어를 특정 순서로 수행하게끔 지정하기 떄문에 멀티 코어나 다중 장비에서의 병렬 처리가 매우 어렵지만, 선언형 언어는 결과의 알고리즘을 지정하는 것이 아닌 결과의 패턴만 지정하기 떄문에 병령 실행으로 더 빨라질 수 있다.
웹에서의 선언형 질의
웹에서도 선언형 질의 언어의 장점이 나타난다.
- 선언형 질의 언어인 웹의 CSS의 경우 selector(선택자)를 통해 스타일 적용하고자 하는 엘리먼트들의 패턴을 선언할 수 있다.
li.selected > p {
background-color: blue;
}
이를 통해 쉽게 패턴에 일치하는 모든 엘리먼트에 스타일을 적용할 수 있다.
- 명령형 접근 방식인 자바스크립트의 코어 DOM(Documemt Object Model) API에서는 엘리멘트의 각종 요소들을 직접 코드로 확인한 후, 엘리먼트에 스타일을 적용한다
var liElements = document.getElementsByTagName("li");
for (var i = 0; i
if (liElements[i].className === "selected") {
var children = liElements[i].childNodes;
for (var j = 0; j
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
child.setAttribute("style", "background-color: blue");
}
}
}
}
이는 패턴이 복잡해질 경우 코드량이 기하급수적으로 늘어나고, 이해하기도 어려워진다는 의미이다. 또한 직접 짠 코드가 잡아내지 못한 예외가 있을 수 있으며, 새로운 기능과 API에 대응하기 위해 코드를 재작성해야 한다는 문제가 생긴다.
웹 브라우저에서 선언형 CSS 스타일을 사용하는 편이 자바스크립에서 명령형으로 스타일을 다루는 것보다 훨씬 낫다. 마찬가리도 데이터베이스 또한 SQL과 같은 선언형 질의 언어가 명령형 질의 API 보다 훨씬 좋다고 나타났다.
맵리듀스 질의
MapReduce(맵리듀스)는 대량의 데이터를 처리하기 위한 프로그래밍 모델로, 일부 NoSQL 데이터 저장소에서는 많은 문서를 대상으로 read-only(일기 전용) 질의를 수행할 때 사용한다.
맵리듀스는 선언형 질의 언어와 명령형 질의 API의 중간에 위치한 언어이다. 질의 로직은 처리 프레임워크가 반복적으로 호출하는 조작 코드로 표현하며, 함수형 프로그래밍 언어에 있는 map과 reduce 함수를 기반으로 한다.
예를 들어 한 달에 얼마나 자주 상어를 발견하는지 보고서를 작성해야 할 때:
- PostgreSQL은 다음과 같이 질의를 표현할 수 있다.
SELECT date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;
- MongoDB은 MapReduce 기능을 이용해 다음과 같이 표현할 수 있다.
db.observations.mapReduce(
function map() { // map은 자바스크립트 함수로, 질의와 일치하는 모든 문서에 대해 한 번씩 호출되며 this는 문서 객체로 설정된다.
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals); // map 함수는 키(연도와 월로 구성된 문자열)과 값(관측치에 있는 동물 수)를 방출(emit)한다.
},
function reduce() { // map이 방출한 키-값 쌍은 키로 그룹화된다. 같은 키(같은 연도와 월)을 갖는 모든 키-값 쌍은 reduce 함수를 한 번 호출한다.
return Array.sum(values); // reduce 함수는 특정 월의 모든 관측치에서 동물 수를 합친다.
},
{
query: { family: "Sharks" }, // 상어 종만 거르기 위한 필터를 선언적으로 지정
out: "monthlySharkReport" // 최종 출력은 monthlySharkReport 컬렉션에 기록한다.
}
)
MongoDB의 map/reduce 함수는 수행할 때 순수 함수여야 하며, 입력된 데이터만 사용하고 추가적인 데이터베이스 질의를 수행할 수 없고, side effect도 없어야 한다. 하지만 이러한 제약 사항이 있어도 문자열 파싱, 파이브러리 함수 호출, 계산 등의 작업을 할 수 있기 때문에 강력한 함수라고 할 수 있다.
맵리듀스는 클러스터 환경에서 분산 실행을 위한 프로그래밍 모델이며 상당히 서수준 프로그래밍 모델이다. 하지만 맵리듀스를 사용하지 않는 분산 SQL 구현도 많다.
맵리듀스의 사용성 문제는 연계된 자바스크립트 함수 두 개를 신중하게 작성해야 한다는 점이다. 이런 이유로 MongoDB에서는 aggregation pipeline(집계 파이프라인)이라고 부르는 선언형 질의 언어 지원을 추가했다.
db.observation.aggregate([
{ $match: { family: "Sharks" },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
}
])집계 파이프라인 언어는 표현 측면에서는 SQL과 비슷하지만, 문장 스타일은 JSON 기반 구문을 사용한다. NoSQL 시스템이 뜻하지 않게 SQL을 재발견하고 있다는 점이 특이점이다.
그래프형 데이터 모델
다대다 관계는 다양한 데이터 모델을 구별하는 중요한 기능이다.
- 애플리케이션이 주로 일다대 관계이거나 레코드 간 관계가 없다면 문서 모델이 적합하다.
- 단순한 다대다 관계라면 관계형 모델이 적합하다.
- 하지만 다대다 관계가 매우 일반적이라면 그래프 데이터 모델이 적합하다.
그래프는 vertex(정점)과 edge(간선) 객체으로 이루어져 있다. 해당 객체들로 많은 유형의 데이터를 그래프로 모델링할 수 있는다.
그래프는 동종 데이터(같은 유형의 데이터)에 국한되지 않고 다른 유형의 객체를 일관성 있게 저장할 수 있는 강력한 방법을 제공한다.
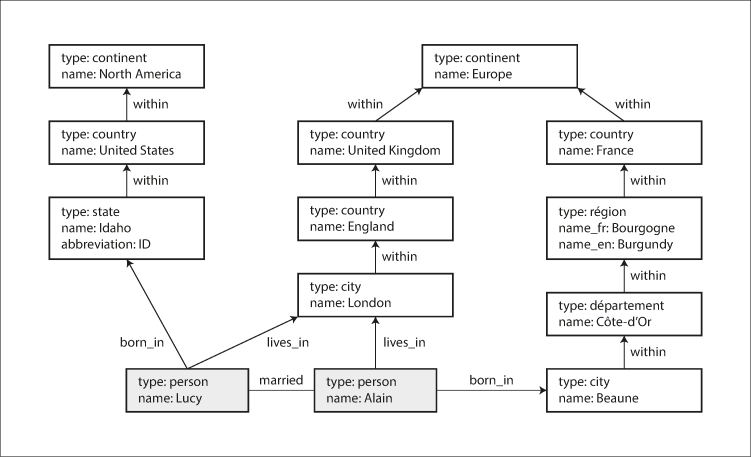
그래프에서 데이터를 구조화하고 질의하는 몇 가지 방법이 있다. 이번 절에서는 다음 모델을 알아본다.
- 속성 그래프 모델
- 트리플 저장소 모델
추가로 그래프용 선언형 질의 언어 세 가지도 살펴본다.
- 사이퍼(Cypher)
- 스파클(SPARQL)
- 데이터로그(Datalog)
속성 그래프
속성 그래프 모델에서 정점은 고유한 식별자, outgoing(유출) 간섭 집합, incoming(유입) 간선 집합, 속성 컬렉션(키-값 쌍)으로 구성되고, 간선은 고유한 식별자, 꼬리 정점, 머리 정점, 두 정점 간 관계 유형을 설명하는 레이블, 속성 컬렉션(키-값 쌍)으로 구성된다.
이 모델에서의 중요한 특성은 다음과 같다.
- 정점은 다른 정점과 간선으로 연결된다. 특정 유형과 관련 여부를 제한하는 스키마는 없다.
- 정점이 주어지면 정점의 유입과 유출 간선을 효율적으로 찾을 수 있고 그래프를 순회할 수 있다. 즉 일련의 정점을 따라 앞 뒤 방향으로 순회한다.
- 다른 유형의 관계에 서로 다른 레이블을 사용하면 단일 그래프에 다른 유형의 정보를 저장하면서도 데이터 모델을 깔끔하게 유지할 수 있다.
이러한 기능들을 통해 그래프는 데이터 모델링을 위한 많은 유연성을 제공한다. 예를 들어 국가마다 지역 구조가 다른 점(프랑스는 departement와 region이지만 미국은 county와 state이다) 등은 전통적인 관계형 스키마에서 표현하기 어렵지만, 그래프로는 쉽게 표현할 수 있다.
또한 그래프를 쉽게 확장할 수 있다. 예를 들어 어떤 사람의 알레르기 정보를 추가하고 싶으면 알리르기 정점을 만든 후 해당 음식이 포함하는 물질들의 정점 집합과 알레르기를 연결하면 해당 사람이 먹으면 안되는 음식을 알아내는 질의 작성을 쉽게 할 수 있다.
사이퍼 질의 언어
Cypher(사이퍼)는 속성 그래프를 위한 선언형 질의 언어이다.
사이퍼에서는 다음과 같은 질의를 수행할 수 있다.
// 미국에서 유럽으로 이민 온 사람을 찾는 사이퍼 질의
MATCH
// person은 어떤 정점을 향하는 BORN_IN 유출 간선을 가진다. 이 정점에서 name 속성이 "United States"인 Location 유형의 정점에 도달할 떄까지 일련의 WITHIN 유출 간선을 따라간다.
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
// 같은 person 정점은 LIVES_IN 유출 간선도 가진다. 이 간선과 WITHIN 유출 간선을 따라가면 결국 name 속성이 "Europe"인 Location 유형의 정점에 도달하게 된다.
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name속성 그래프에서는 이러한 유형의 질의를 수행할 수 있으며, 질의에 대한 수행은 질의 최적화기가 가장 효율적이라고 예측한 전략을 자동으로 선택하기 때문에, 작성자는 나머지 애플리케이션만 작성하면 된다.
SQL의 그래프 질의
그래프 데이터를 관계형 구조로 넣어도 SQL를 사용해 질의할 수 있지만, 매우 복잡해진다.
관계형 데이터베이스에서는 질의에 필요한 조인을 미리 알고 있지만, 그래프 질의에서는 찾고자 하는 정점을 찾기 전에 가변적인 여러 간선을 순회해야 하기 때문에 조인 수를 고정할 수 없다.
사이퍼에서의 간선 순회는 () -[:WITHIN*0..]-> 문에서 수행하는데, *0 연산으로 0회 이상 WITHIN 간선을 따라가라라는 의미를 가지고 있다.
SQL:1999 이후로 가변 순회 경로에 대한 질의 개념은 recursive common table expression(재귀 공통 테이블 식, WITH RECURSIVE문)으로 표현할 수 있지만, 사이퍼와 비교하면 문법이 매우 어렵다.
WITH recursive -- in_usa is the set of vertex IDs of all locations within the United States in_usa(vertex_id) AS (SELECT vertex_id
FROM
vertices
WHERE
properties ->> 'name' = 'United States' �
UNION
SELECT
edges.tait_vertex
FROM
edges 0
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE
edges.tabet = 'within'
),
-- in_europe is the set of vertex IDs of all locations within Europe in_europe(vertex_id) AS (SELECT vertex_id
FROM
vertices
WHERE
properties ->> 'name' = 'Europe' �
UNION
SELECT
edges.tait_vertex
FROM
edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE
edges.tabet = 'within'
),
-- born_in_usa is the set of vertex IDs of all people born in the US born_in_usa(vertex_id) AS ( ОSELECT edges.tait_vertex
FROM
edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE
edges.tabet = 'born_in'
),
-- lives_in_europe is the set of vertex IDs of all people living in Europe lives_in_europe(vertex_id) AS ( ©SELECT edges.tail_vertex
FROM
edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE
edges.label = 'lives_in'
)
SELECT
vertices.properties ->> 'name'
FROM
vertices -- join to find those people who were both born in the US *and* live in Europe JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id ©
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;동일한 질의를 사이퍼에서는 4줄로, SQL에서는 29줄로 작성해야 한다는 점에서, 다양한 데이터 모델이 서로 다른 사용 사례를 만족하기 위해 설계됐다는 사실을 보여준다. 따라서 애플리케이션에 적합한 데이터 모델을 선택하는 작업은 중요하다.
트리플 저장소와 스파클
트리플 저장소 모델은 속성 그래프 모델과 거의 동등하다. 이 모델은 같은 생각을 다른 용어를 사용해 설명한다.
@prefix : .
_:lucy a :Person; :name "Lucy"; :bornIn _:idaho.
_:idaho a :Location; :name "Idaho"; :type "state"; :within _:usa.
_:usa a :Location; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".위의 코드는 Turtle(터틀) 형식의 트리플로 작성되었다. 이 모델은 모든 정보를 subject(주어), predicate(서술어), object(목적어)의 three-part statements(세 부분 구문) 형식으로 저장한다. 여기서 주어는 그래프의 정점과 동등하고, 목적어는 primitive type이거나 그래프의 다른 정점이다.
시멘틱 웹
시멘틱 웹은 웹 사이트가 사람이 읽을 수 있는 형태로 정보를 게시하고 있으니, 기계가 판독 가능한 데이터로도 정보를 게시하는 것이 어떨까라는 개념이다.
RDF (Resource Description Framework, 자원 기술 프레임워크)에서 일관된 형식으로 데이터를 게시하기 위한 방법을 제안했지만, 여러가지 단점들로 인해 시멘틱 웹은 어려움을 겪었다.
하지만 시맨틱 웹 프로젝트에서 유래한 좋은 작업들이 많이 있다.
RDF 데이터 모델
터틀 언어로 작성한 데이터를 RDF/XML 형식으로 쓰기도 한다. 하지만 XML 형식은 내용을 장황하게 만들기 때문에, 한 눈에 쉽게 보니 위해서는 터틀을 선호한다.
RDF에서 주목할 점은 트리플의 주어, 서술어, 목적어가 주로 URI라는 점이다. 이는 데이터를 다른 사람의 데이터가 결합하기 위해서이다.
스파클 질의 언어
SPARKQL(스파클, SPARQL Protocol and RDF Query Lanauge)는 RDF 데이터 모델을 사용한 트리플 저장소 질의 언어다.
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
// Cypher의 (person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) 표현식과 동등함
?person :bornIn / :within* / :name "United States".
?person :tivesIn / :within* / :name "Europe".
}스파클은 사이퍼의 패턴 매칭을 차용했기 떄문에 구조가 매우 유사하다. 또한 RDF는 속성과 간선을 구별하지 않고 서술어만 사용하기 때문에 속성 매칭을 위해 동일한 구문을 사용할 수 있다.
스파클은 시맨틱 웹이 아니더라도 애플리케이션이 내부적으로 사용하는 강력한 도구가 될 수 있는 훌륭한 질의 언어다.
추석: 데이터로그
Datalog(데이터로그)는 스파클이나 사이퍼보다 훨씬 오래된 언어며 1980년 학계에서 광범위하게 연구됐다. 이 언어가 중요한 이유는 이후 질의 언의의 기반이 되는 초석을 제공하기 때문이다.
데이터로그의 데이터 모델은 트리플 저장소 모델과 유사하지만 조금 더 일반화되어, 주어/목적어로 작성한다.
// 데이터 작성
name(namerica, 'North America'). type(namerica, continent).
name(usa, 'United States'). type(usa, country). within(usa, namerica).
// 데이터 질의
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */
within_recursive(Location, Name) :- within(Location, Via), /* Rule 2 */
within_recursive(Via, Name).
migrated(Name, BornIn, LivingIn) :- name(Person, Name), /* Rule 3 */
born_in(Person, BornLoc),
within_recursive(BornLoc, BornIn),
tives_in(Person, LivingLoc),
within_recursive(LivingLoc, LivingIn).
?- migrated(Who, 'United States', 'Europe').
/* Who = 'Lucy'. */사이퍼와 스파크는 SELECT로 바로 질의하는 반면, 데이터로그는 단계를 나눠 한 번에 조금씩 질의로 나아간다.
서술어를 데이터베이스에 전달하는 규칙(rule, within_recursive/migrated)을 통해 규칙이 다른 규칙을 참조하면서 복잡한 질의를 작은 부분으로 나눠 차례차례 구성할 수 있다.
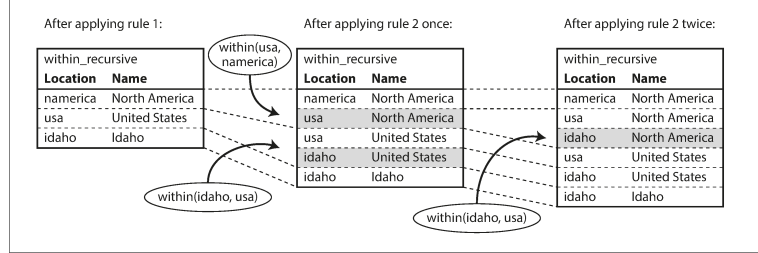
이런 방식으로 규칙을 반복 적용하여 답을 얻는다.
데이터로그의 접근 방식은 다른 질의 언어와는 다르지만, 질의의 규칙을 결합하거나 재사용할 수 있기 때문에 매우 강력한 접근 방식이다. 간단한 일외성 질의에 사용하기는 편리하지 않지만 데이터가 복잡하면 더 효과적으로 대처할 수 있다.
정리
데이터 모델은 광범위한 주제이고, 이번 장에서는 다양한 종류의 모델을 간략하게 살펴봤다.
역사적으로 데이터를 하나의 큰 트리(계층 모델)로 표현하려고 노력했지만 다대다 관계를 표현하기에는 트리 구조가 적절하지 않았다.
이 문제를 해결하기 위해 관계형 모델이 고안되었고, 최근에는 관계형 모델에도 적합하지 않은 애플리케이션이 있다는 사실을 발견하였다.
이를 해결하기 위해 비관계형 데이터저장소인 NoSQL가 등장하였는데, NoSQL에는 두 가지 주요 갈래가 있다.
- 문서 데이터베이스는 데이터가 문서 자체에 포함돼 있으면서 하나의 문서와 다른 문서 간 관계가 거의 없는 사용 사례를 대상으로 한다.
- 그래프 데이터베이스는 문서 데이터베이스와는 정반대로 모든 것이 잠재적으로 관련 있다는 사용 사례를 대상으로 한다.
세 가지 모델(문서, 관계형, 그래프) 모두 현재 널리 사용하고 있으며, 각 모델은 각자의 영역에서 훌륭하다.
한 모델을 다른 모델로 흉내 낼 수 있지만, 그 결과는 대부분 엉망이다. 이것이 바로 단일 만능 솔루션이 아닌 각기 목적에 맞는 다양한 시스템을 보유해야 하는 이유다.
문서 및 그래프 데이터베이스가 가진 공통점 중 하나는 일반적으로 저장할 데이터를 위한 스키마를 강제하지 않아 변화하는 요구사항에 맞춰 애플리케이션을 쉽게 변경할 수 있다는 점이다. 하지만 애플리케이션은 데이터가 특정 구조를 갖는다고 가정할 가능성이 높고, 스키마가 명시적인지(쓰기에 강요됨) 암시적인지(읽기에 다뤄짐)의 문제일 뿐이다.
각 데이터 모델은 고유한 질의 언어나 프레임워크를 제공한다. 예로 SQL, MapRedue, MongoDB Aggregated Pipeline, Cyhper, SPARQL, Datalog 등이 있다.
이 장에서 언급되지 않는 많은 데이터 모델들이 있는데, 몇 가지 예를 들자면 다음과 같다.
- 게놈(genome) 데이터로 작업하는 연구원은 하나의 아주 긴 문자열을 가지고, 유사하지만 동일하지 않은 문자열을 대용량 문자열 데이터베이스에서 찾아야 하기 때문에 GenBank(젠뱅크)라는 특화된 게놈 데이터베이스 소프트웨어를 작성했다.
- 입자 물리학자들이 수행하는 대형 강입자 충돌기 (LHC)와 같은 프로젝트의 작업은 데이터 규모가 현재 수백 페타바이트에 달하기 때문에, 별도의 사용자 정의 솔루션이 필요하다.
- full-text(전문) 검색 또한 데이터베이스와 함께 자주 사용되는 일종의 데이터 모델이다.
Reference: http://www.yes24.com/Product/Goods/59566585
데이터 중심 애플리케이션 설계 - YES24
데이터는 오늘날 시스템을 설계할 때 마주치는 많은 도전 과제 중에서도 가장 중심에 있다. 확장성, 일관성, 신뢰성, 효율성, 유지보수성과 같은 해결하기 어려운 문제를 파악해야 할 뿐 아니라
www.yes24.com
'백엔드 > 분산 시스템' 카테고리의 다른 글
| [데이터 중심 애플리케이션 설계] Part 1. 데이터 시스템의 기초 (0) | 2023.01.22 |
|---|---|
| [데이터 중심 애플리케이션 설계] 04장. 부호화와 발전 (0) | 2023.01.15 |
| [데이터 중심 애플리케이션 설계] 03장. 저장소와 검색 (0) | 2023.01.09 |
| [데이터 중심 애플리케이션 설계] 01장. 신뢰할 수 있고 확장 가능하며 유지보수하기 쉬운 애플리케이션 (0) | 2022.12.26 |
| [데이터 중심 애플리케이션 설계] 00장. 머리말 (0) | 2022.12.26 |